
背景
KCNA-JP (Kubernetes and Cloud Native Associate) に一発合格したのでそれについて述べていきます。
- Kubernetesについてはほぼ触れたことがない状態から勉強を始めました。
- AWS のSAPをとっているのでCloudそのものについては知識と経験があります。

学習材料
まずはこちらの本でサラッとKubernetesに触れました。分量もそこまで多くなく、Kubernetesのコマンド(kubectl)を実際に叩いて色々Hands-Onでできたのが良かったです。
次にこちらのUdemyの授業を一周し、付属しているpractice examで練習しました。
こちらのudemyの授業にもHands-Onが多くとても学びやすかったです。またpractice examの問題も実際に結構出題されていました(ただし英語授業となります。)
その後udemyでこちらの日本語での演習テストを購入して一周しました。
こちらの問題は生成AIで作ったのかの様な少し不自然なところもありました。問題に正解するというよりは登場したワードをきちんと理解しているかを確認するのにいいかと思います。
以下の「試験用メモ」セクションは自分なりに調べてまとめた集大成のようなものです
こちらを活用するのも非常に有効です。
感想
75%で合格ですが、合格自体はそれほど難しくないかと思います。問題も英語と日本語で切り替えられるので、気になった部分は英語を確認するのがオススメです。
それよりも多くの方が言っているのですが、受験するまでが難しいです。
こちらの方の受験するためのメモを参考にするのが良いかと思います。

私の場合英語での意思疎通の部分は問題なかったのですが、試験開始時刻から試験官が来るまでなんと20分も待たされました。その間テクニカルサポートと連絡は取れたのですが、試験管理側はとても杜撰な印象です。正直テストセンターで受ける形式を導入して欲しいです。
試験用メモ
Basic
Workload
クラスター上で実行されるアプリケーションやプロセスの総称で、Pod、Deployment、StatefulSet、DaemonSet、Job、CronJobなどのリソースを含む。これらのワークロード
リソースはPodの作成・管理・スケーリング・更新を自動化し、それぞれ異なる用途に特化している
(例:Deploymentはステートレスアプリ、StatefulSetはステートフルアプリ)。
ワークロードによって、アプリケーションの可用性、スケーラビリティ、信頼性がKubernetes上で実現される。
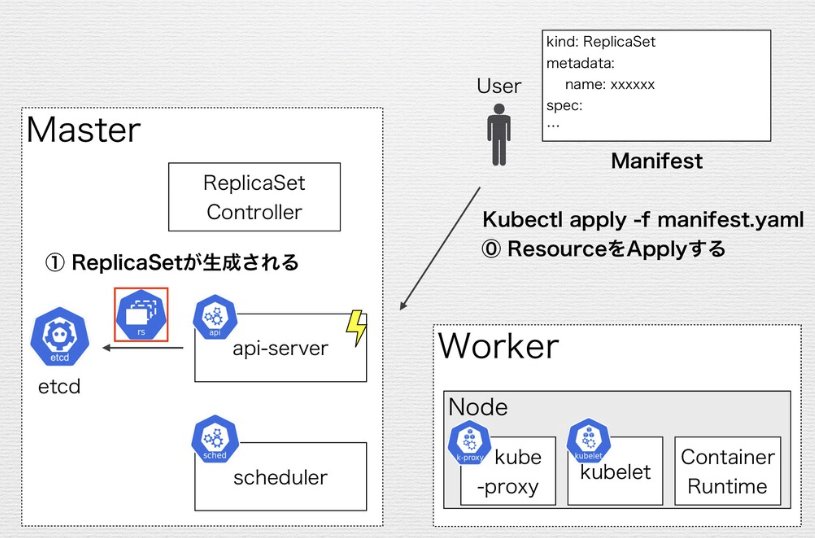
api-serverとcontroller-manager
- api-server: DeploymentやServiceなどのObjectの作成、更新、削除(CRUD)のリクエストを受け取り、操作を行う。
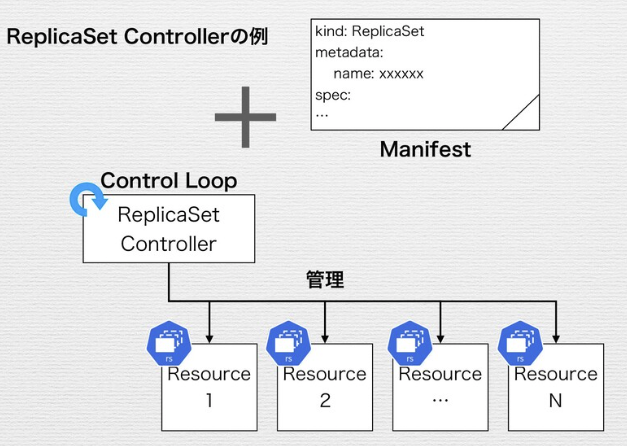
Objectの情報をデータストアであるetcdに格納する。(etcdにアクセスするコンポーネントはapi-serverのみ) - controller-manager: DeploymentやService などのObjectの管理を行う。controll-managerはCotroller群のかたまり。以下の様に1つのプロセスに複数のControllerがある。
そしてControllerがResourceの管理を行う。
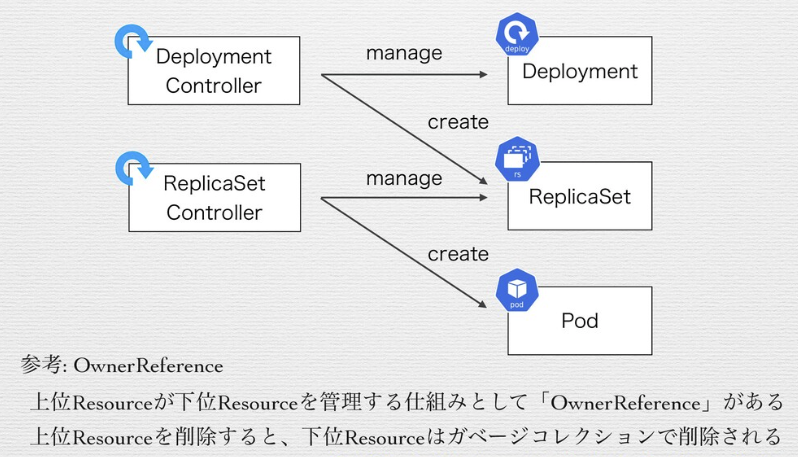
Controllerはそれに対応する1つのResourceを管理する。(以下の様にDeployment ControllerはDeployment、ReplicaSet ContollerはReplicasetを管理)
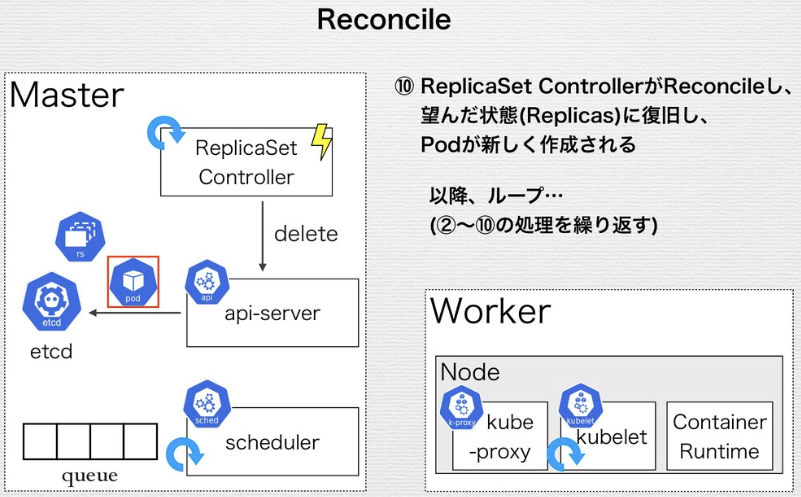
Control Loop (Reconciliation Loop)
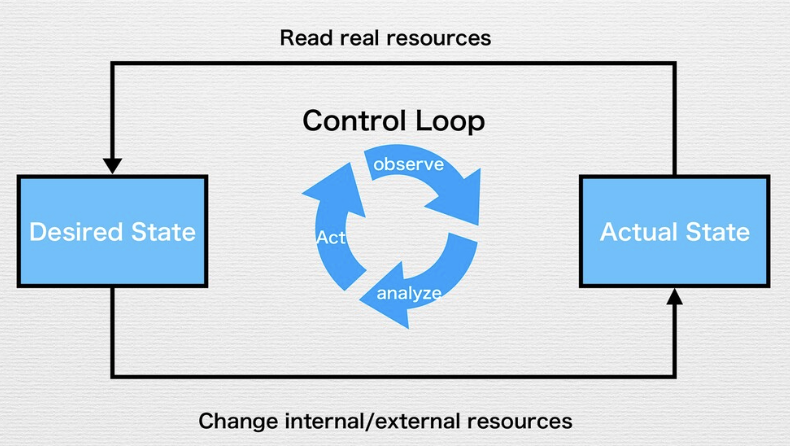
Control Loopの流れ
- Resourceの現在の状態(Actual State)を読み込む
- Resourceを望んだ状態(Desired State)に変更する
- Resourceの状態(Status)を更新する
Control Loopによって、望んだ状態を宣言することで環境が構築される。
→ Immutable Infrastuctureが実現できる
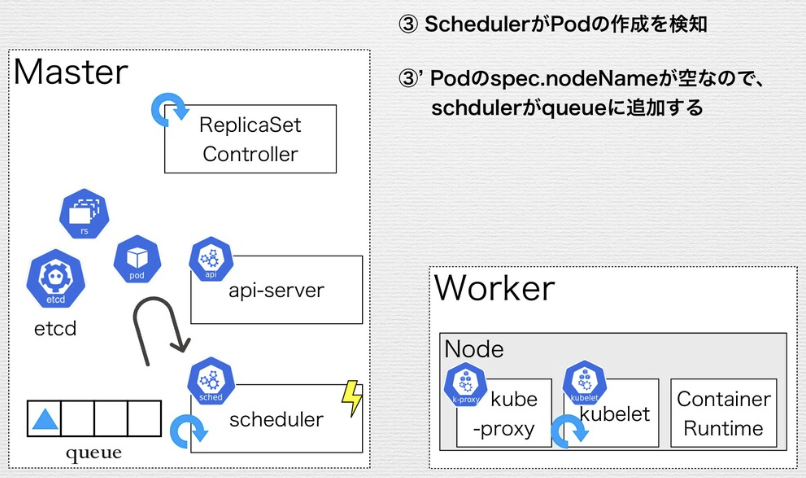
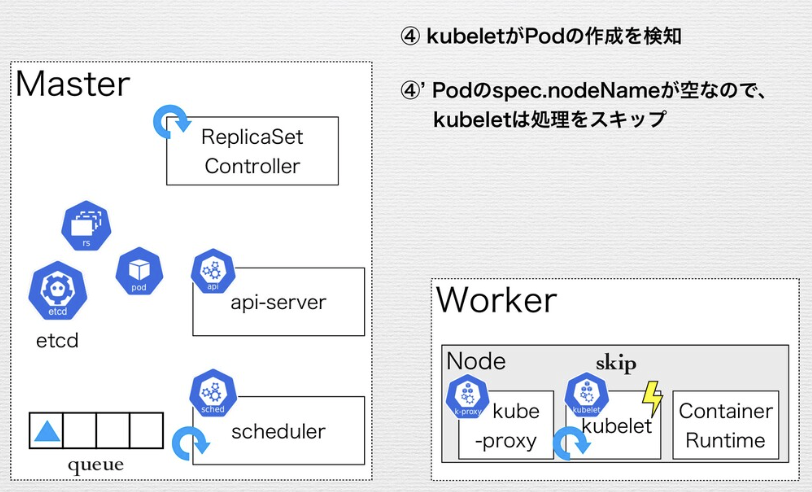
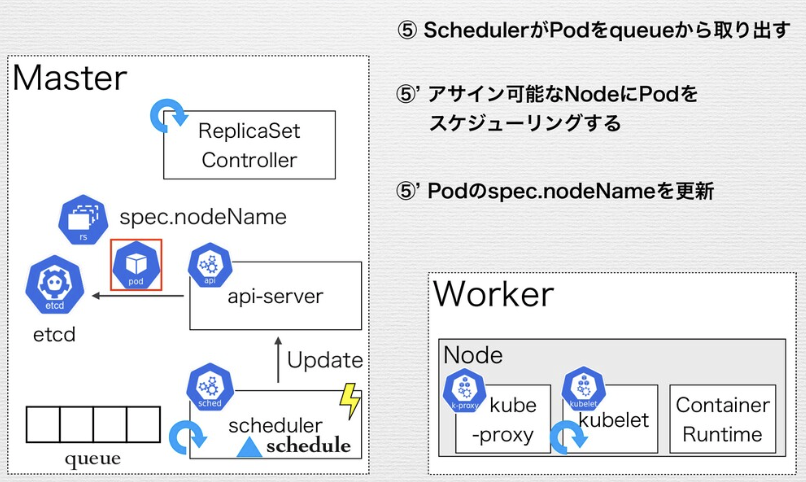
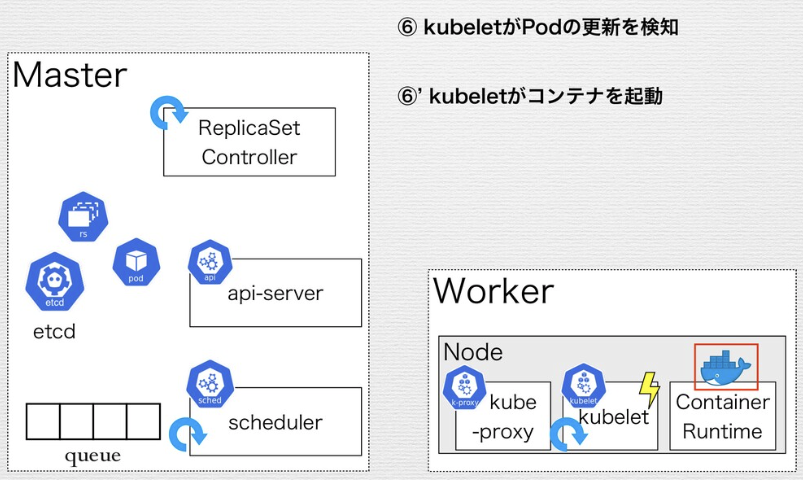
ReplicaSetのControl Loopの例
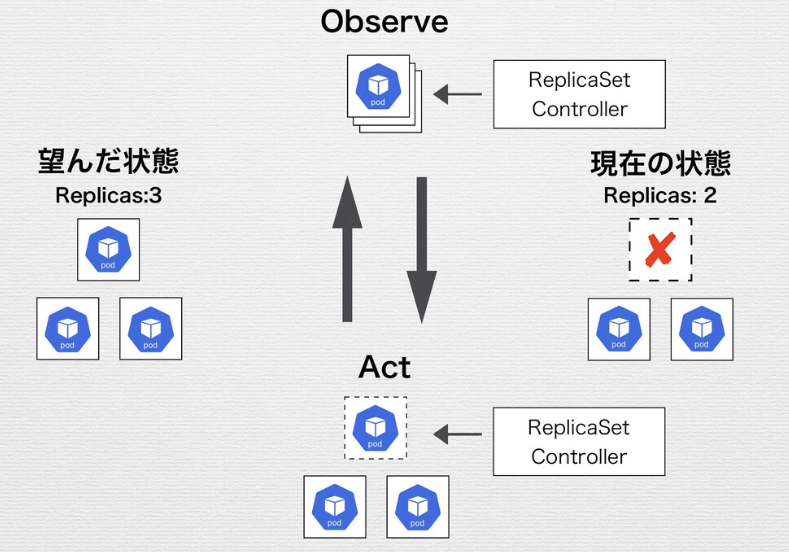
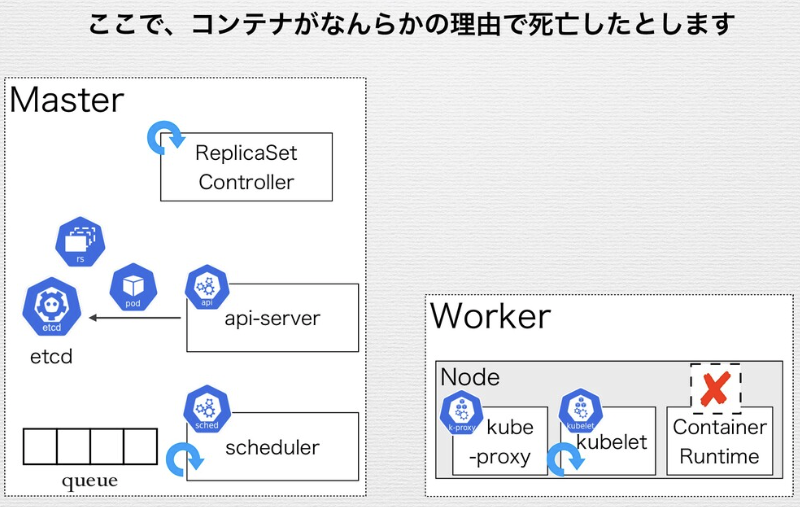
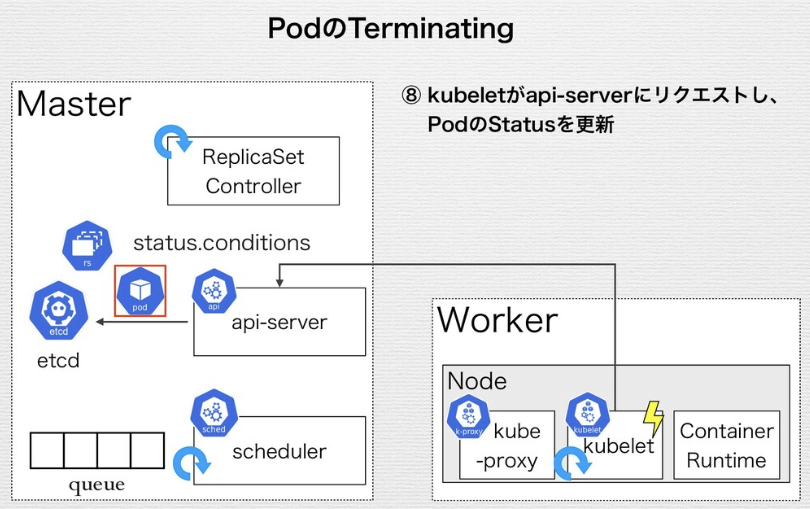
Replica SetがApplyされ、デリバリされるまでの流れ
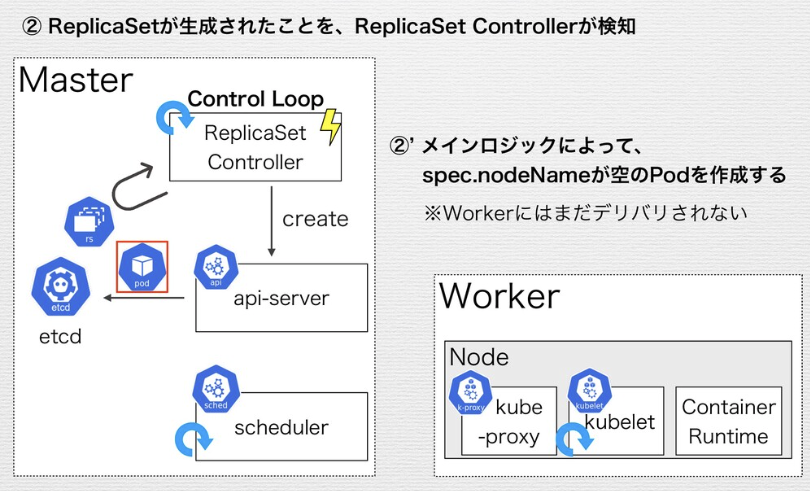
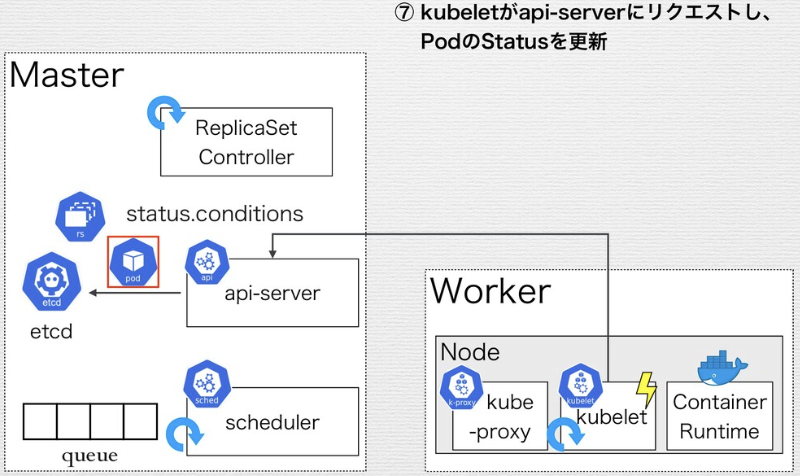

kube-node-lease namespaceとノードのハートビート
- kube-node-lease: v1.14以降でデフォルトで作成されるようになったnamespace。
Nodeのハートビートを監視するためのleaseオブジェクトというリソースが入る。他のコンポーネントはこのleaseオブジェクトの状態を監視することでNodeの正常性を確認する。 - ハードビート: Kubernetesノードから送信され、ノードが利用可能か判断するのに役立つ。 以下の2つのハートビートがある。
- Nodeの
.statusの更新 - Lease object。各ノードは
kube-node-leaseというnamespaceに関連したLeaseオブジェクトを持つ。 Leaseは軽量なリソースで、クラスターのスケールに応じてノードのハートビートにおけるパフォーマンスを改善する。
- Nodeの
kube-node-lease namespaceは以下の様に確認できる
$ kubectl get ns
NAME STATUS AGE
default Active 3d
kube-node-lease Active 3d
kube-public Active 3d
kube-system Active 3d
local-path-storage Active 3dcontainerdとrunc
- containerd:
コンテナのライフサイクル管理(作成・開始・停止・削除)を担当する。
コンテナの元となるイメージ(テンプレートみたいなもの)を取得・保存する。(イメージ管理)
Kubernetes などのシステムが containerd を使ってコンテナを操作できるようにAPIを提供する。 - runC:
コンテナを実際に起動・実行する。
Linux の機能(Namespaces や cgroups)を使ってコンテナを隔離する。
Dockerおよび Kubernetesでコンテナが起動する際の流れ
# Docker
Docker CLI → Docker Engine → containerd → runC → Linux Namespaces & cgroups
# Kubernetes
Kubernetes (kubelet) → containerd → runC → Linux Namespaces & cgroupsOpen Container Initiative (OCI)
コンテナの標準化を推進するLinux Foundationのプロジェクトで、Docker、Red Hat、Googleなどの主要企業が参加している。OCIは主にコンテナイメージの形式を定める「Image Specification」と、コンテナの実行時仕様を定める「Runtime Specification」の2つの標準を策定している。
これにより、異なるコンテナランタイム(Docker、containerd、CRI-Oなど)間でのコンテナイメージの互換性と移植性を確保している。
CRI-O
コンテナ型仮想化は、OCI(Open Container Initiative) Runtime Specification、OCI Image Format Specification、CRI(Container Runtime Interface)などの規定によって、アーキテクチャーが標準化されている。
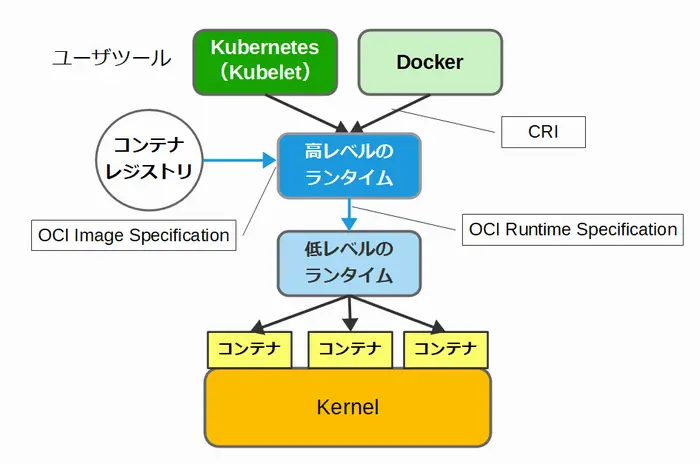
containerdがDockerとKubernetesから利用できる汎用のランタイムであるのに対して、CRI-OはKubernetesに最適化させた軽量なランタイムとして開発された。どちらも高レベルのランタイムに属する。
cgroups
Linux カーネルの機能の1つであり、プロセスやスレッドが利用するリソースの制限や分離を行うための機能。 cgroupは生成されたコンテナ上のプロセスを1つのcgroupとして扱う。そのため、コンテナ単位でPID/CPU/メモリ使用量/ネットワークを制限し分離できる。
Kata Container
Kata Containerとは、コンテナ型仮想化で使われる技術の1つで、OCI Runtime Specificationに基づいて作られたKubernetesやDockerの低レベルなランタイム。
低レベルのランタイムとしては、Dockerのコードから分離して作られのがrunc。runcでは、すべてのコンテナが1つのカーネルを共有して動作する。そのため、不適切なコンテナが存在した場合には、他のコンテナに影響が及ぶ可能性があり、セキュリティ的に脆弱だと懸念されている。
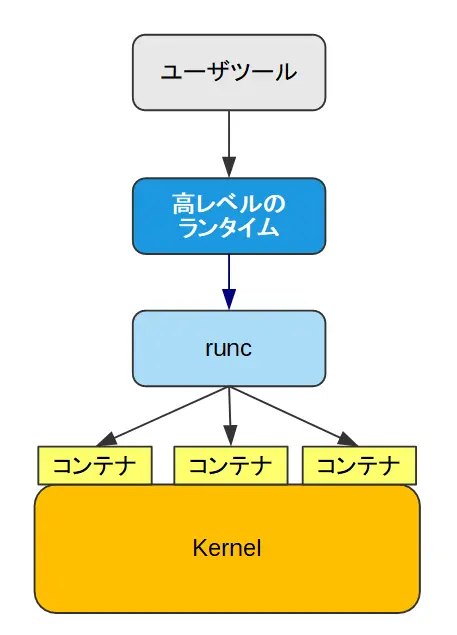
Kata Containerは、こうしたruncのセキュリティの問題を改善するために開発されたランタイム。
仮想化の技術を利用して作成した軽量なハイパーバイザーの上で動作し、コンテナ個別にカーネルを動作させることで、コンテナ間の分離を実現する。
動作には、ハイパーバイザーとの連携が必要となる。QEMU、NEMUなどのハイパーバイザーがサポートされている。

gVisor
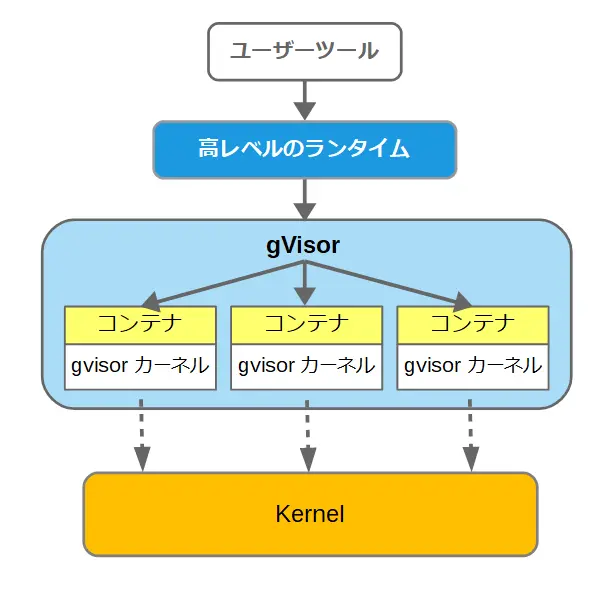
gVisorとは、コンテナ型仮想化で使われる技術の1つで、OCI Runtime Specificationに基づいて作られたKubernetesやDockerの低レベルなランタイム。
gVisorは、Go言語で書かれたユーザスペースで動くカーネルと紹介されている。Google社が開発し、オープンソースとして公開されている。runcのセキュリティの問題を解消するために開発された。
低レベルのランタイムとしては、Dockerのコードから分離して作られたruncがある。runcでは、すべてのコンテナが1つのカーネルを共有して動作する。そのため、不適切なコンテナが存在した場合には、他のコンテナに影響が及ぶ可能性があり、セキュリティ的に脆弱だと懸念されている。
gVisorは、コンテナの動作に必要なシステムコールの多くを、直接ホストカーネルに渡さず、ユーザ空間で処理する。ただし、ハードウェアに関連する一部のシステムコールだけは、ホストカーネルに処理を委ねる構造になっている。
このような構造によって、gVisorは、ホストカーネルとコンテナを切り離し、コンテナをサンドボックス化することができまる。
gVisorは、Linuxでのみ動作する。
Initコンテナ
Initコンテナは、Pod内でアプリケーションコンテナが起動する前に実行される特別なコンテナで、セ
ットアップスクリプトやユーティリティを含められる。
複数のInitコンテナがある場合は順番に実行され、各Initコンテナは次が開始される前に正常完了する必要がある。Initコンテナが失敗した場合、Kubeletは成功するまで再起動を繰り返す(restartPolicyがNeverの場合はPod全体が失敗扱い)。
通常のコンテナと同じ機能をサポートするが、lifecycle、livenessProbe、readinessProbe、startupProbeは使用できない。すべてのInitコンテナが完了すると、アプリケーションコンテナが通常通り起動する。
Cluster Autoscaler, Horizontal Pod Autoscaler (HPA), Vertical Pod Autoscaler (VPA)
| 機能 | スケール対象 | スケール基準 |
|---|---|---|
| Cluster Autoscaler | ノード数 | リソース不足、余剰 |
| Horizontal Pod Autoscaler (HPA) | ポッド数 | CPU使用率、メモリ使用率などのメトリクス |
| Vertical Pod Autoscaler (VPA) | ポッドのリソース要求量 | 過去のメトリクス |
- Cluster Autoscaler:
クラスタ全体のノード数を自動的に調整する。リソース不足でポッドがスケジュールできない場合に、新しいノードを追加したり、逆にリソースが余っている場合にノードを削除したりする。ノードレベルのオートスケーリングを担当。
- Horizontal Pod Autoscaler (HPA):
ポッドのレプリカ数を自動的に調整する。CPU使用率やメモリ使用率などのメトリクスに基づいてポッドの数を増減させる。
ポッドレベルのオートスケーリングを担当。 - Vertical Pod Autoscaler (VPA):
ポッドが要求するリソース(CPUやメモリ)の量を自動的に調整する。過去のメトリクスを分析し、最適なリソース要求量を提案または適用する。
VPAは、HPAと組み合わせて使用することで、より効果的にリソースを管理できる。
kubernetes podのマルチコンテナでのコンテナデザインパターン
- サイドカーパターン:
メインのコンテナと、補助的な機能を提供するコンテナで構成される。
補助的な機能とは、以下の図のような、ログファイルを転送するコンテナ、Gitリポジトリの更新をローカルのストレージに反映するコンテナなどが該当。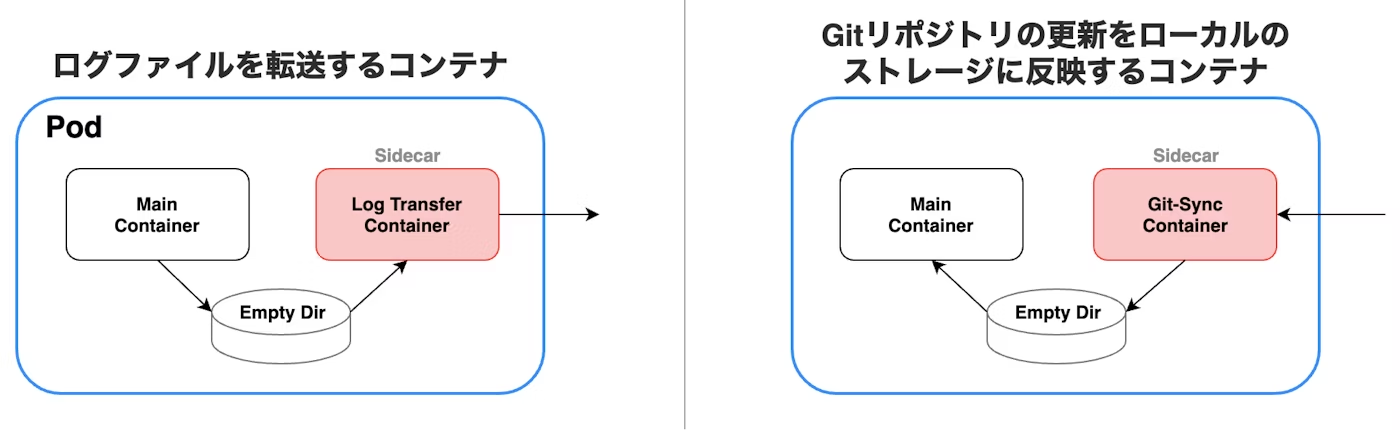
- メインコンテナには優先的にCPUを割り当て、低レイテンシで応答させることができる
- コンテナはパッケージングの単位なので、コンテナに分けることで、2つのチームに開発の責任を簡単に分担することができ、独立してテストできる
- コンテナは再利用でき、サイドカーコンテナは複数の異なるメインコンテナと組み合わせることができる
- コンテナは障害を封じ込める境界線を提供し、障害がシステム全体に波及することを防ぐことができる
- コンテナはデプロイの単位であり、各機能をアップグレードしたり、必要に応じてロールバックすることができる
- アンバサダーパターン:
アンバサダーパターンは、メインのコンテナと、外部システムとの接続を中継するコンテナで構成される。
例えば、データベースや、S3やGCPなどのオブジェクトストレージと接続するアプリケーションがあるとする。アンバサダーパターンを用いることなく実装した場合は、接続先の情報を環境変数に設定するなどして、アプリケーションのコンテナから直接接続することが一般的だが、これではアプリケーションと外部システムの結合度が強くなってしまう。
しかし、アンバサダーパターンを用いると、その結合度を下げることができる。外部システムと接続するのはアンバサダーコンテナに任せ、アプリケーションのコンテナはlocalhostを指定して、アンバサダーコンテナに接続する。これにより、アプリケーションは環境による差異を考慮する必要がなくなる。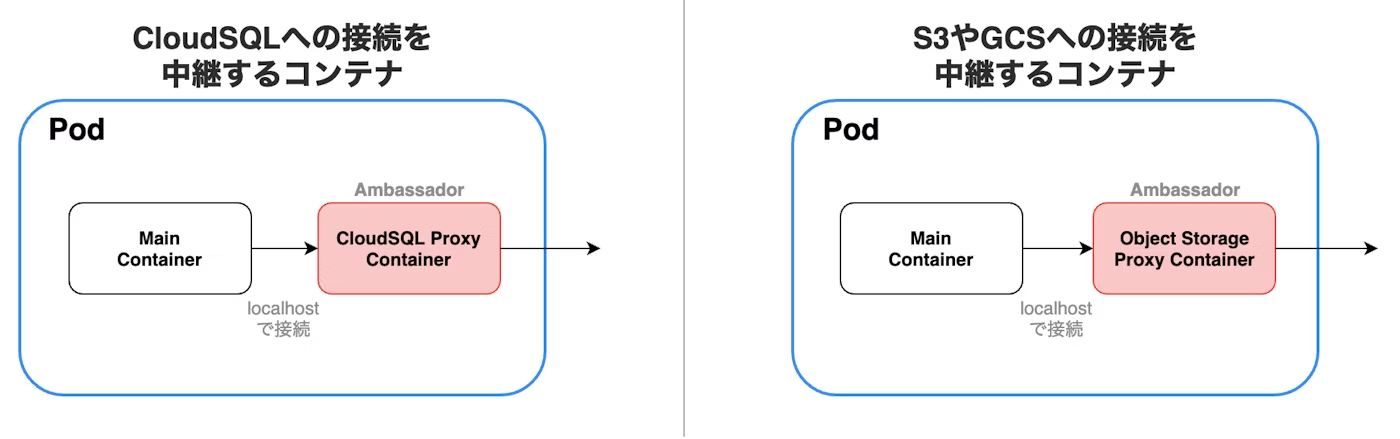
- アダプターパターン:
アダプターパターンは、メインのコンテナと、外部システムからの接続を中継するコンテナで構成される。
以下の図のような、レガシーアプリケーションを含む複数のアプリケーションのPodに対して、統一されたインターフェースを提供できる。
Static PodとDaemon Set
- Static Pod:
Static Pod はkubelet によって直接管理されるPod。コントロールプレーンによって管理されるPod(例えばDeploymentなどで配置されたもの)は kube-apiserver によって管理されるが、Static Pod は kube-apiserver を介さず kubelet が直接管理する。
Static Pod は必ずいずれかのノードの kubelet に紐付けられている。kubelet は自動的に各 Static Pod に対応する mirror pod を kube-apiserver 上に作成する。これにより、Static Pod は kube-apiserver から見えるようになる(=kubectl コマンドなどで 確認することができるようになる)。
しかし、mirror pod に操作を加えることはできず、”kubectl delete pod” などをしても Static Pod の実体は消えない(mirror pod を消しても、実体を元にしてすぐに復活する)。また、Static Pod はクラッシュした場合にも自動的に再起動される。 - Daemon Set:
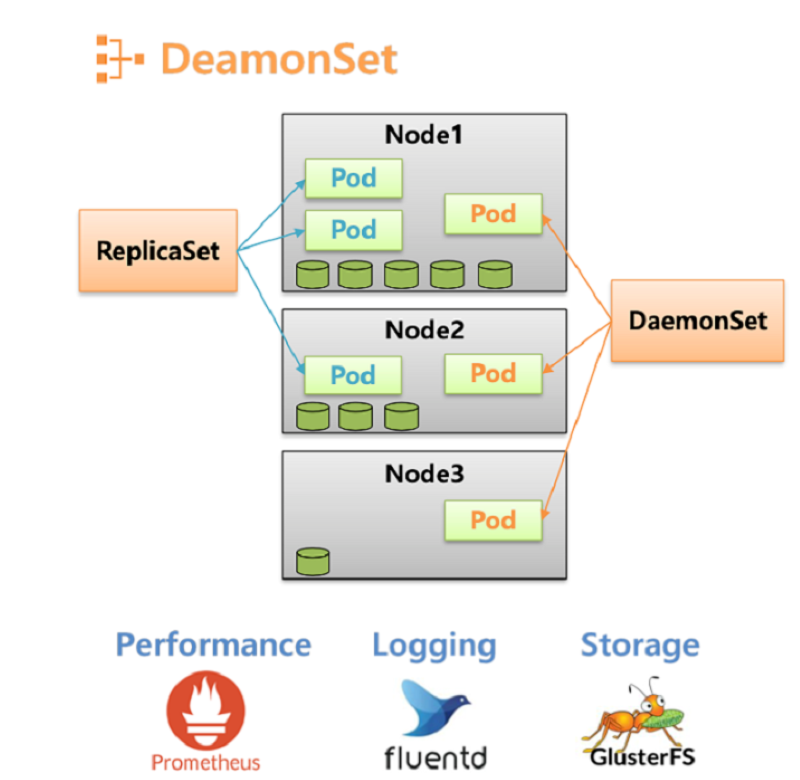
DaemonSetはKubernetesクラスタ内の各ノード( Node )で特定の Pod が常に実行されるように保証する役割を果たすワークロードリソース。
DaemonSet は、Node がクラスタに追加されるとき、その Node 上に特定の Pod を作成する。また、Node がクラスタから削除されると、 DaemonSet が作成した Pod はガベージコレクタにより削除される。
これにより、ログ収集やモニタリングなどの機能をクラスタ内のすべてのノードで一貫して実行することが可能になる。DaemonSet は各 Node で単一の Pod のコピーを稼働させるという特性から、以下のような用途に特に適している。
- ログ収集:
各 Node 上でログ収集デーモン(例えば、FluentdやLogstash)を稼働させ、ログ情報の収集と保存を行う。
- モニタリング:
各 Node のパフォーマンス情報の監視、収集と保存を行う。モニタリング用ソフトウェアには Prometheus Node Exporter 、 collectd 、 Datadog Agent などがある。
- 分散ストレージ:
分散ストレージソフトウェア(例えば、Ceph、Gluster、Longhorn)を運用する際にも利用される。ここで言うストレージは、 Kubernetes を用いて構築されるストレージを指す。
- ログ収集:
Static PodとDaemonSet の違い
”各ノードにPodを1つずつ配置する” という特徴は同じでだが、次のような違いがある。
- DaemonSet は kubectl などの Kubernetes API クライアントで管理できるが、Static Pod はできない。
- DaemonSet は kube-apiserver に依存するが、Static Pod は依存しない。そのため、Static Pod はクラスターのブートストラップ時に便利。
Kubernetes公式ドキュメント によると Static Pod は今後廃止される可能性がある。(廃止して Static Pod で管理していた Pod はすべて DaemonSet での管理に移行する予定?)
RuntimeClass
RuntimeClassはコンテナランタイムの設定を選択するための機能。そのコンテナランタイム設定はPodのコンテナを稼働させるために使われる。
異なるPodに異なるRuntimeClassを設定することで、パフォーマンスとセキュリティのバランスをとることができる。例えば、ワークロードの一部に高レベルの情報セキュリティ保証が必要な場合、ハードウェア仮想化を使用するコンテナランタイムで実行されるようにそれらのPodをスケジュールすることを選択できる。その後、追加のオーバーヘッドを犠牲にして、代替ランタイムをさらに分離することでメリットが得られる。
RuntimeClassを使用して、コンテナランタイムは同じでも設定が異なるPodを実行することもできる。
Kubernetes container restart policies
- Always: コンテナが終了または停止した場合、常に再起動されることを意味する。
- OnFailure: コンテナがゼロ以外のステータスコードで終了し、失敗を示す場合のみ再起動されることを意味する。
- Never: コンテナが終了または停止した後、決して再起動されないことを意味する。
kubernetes secret の Opaqueタイプ
最も一般的で汎用的なSecretタイプ。任意のユーザー定義データを格納でき、データ形式に特別な制約がない。
データはbase64エンコードされて保存されるが、これは暗号化ではなく単なるエンコーディング。
パスワード、APIキー、証明書など、様々な機密情報の保存に使用可能。
他の特定用途のSecretタイプ(kubernetes.io/tls、kubernetes.io/dockerconfigjsonなど)と異なり、データ構造の検証は行われない。
Pod Disruption Budgets (PDBs)
PDBはローリングアップデートやスケーリングなどの自発的な中断から保護するためにKubernetesに導入された機能。その主な機能はこれらの中断中に利用可能なレプリカの最小数を維持し、一定レベルのサービス可用性が常に維持されることを保証する。
kubernetes dashboard
kubernetes dashboardはWebベースのKubernetesユーザーインターフェース。
ダッシュボードを使用して、コンテナ化されたアプリケーションをKubernetesクラスターにデプロイしたり、 コンテナ化されたアプリケーションをトラブルシューティングしたり、クラスターリソースを管理したりすることができる。
ダッシュボードを使用して、クラスター上で実行されているアプリケーションの概要を把握したり、 個々のKubernetesリソース(Deployments、Jobs、DaemonSetsなど)を作成または修正したりすることができる。 たとえば、Deploymentのスケール、ローリングアップデートの開始、Podの再起動、 デプロイウィザードを使用した新しいアプリケーションのデプロイなどが可能。
ダッシュボードでは、クラスター内のKubernetesリソースの状態や、発生した可能性のあるエラーに関する情報も提供される。
Manifest
immutable:true
Kubernetesでは、ConfigMapとSecretはimmutable:true属性を利用して、作成後にデータが変更できないことを保証できる。この属性がtrueに設定されると、ConfigMapやSecretを更新しようとする試みはすべてエラーになる。
Kubectl command
マルチコンテナpodの内の終了した(Crashまたはrestartした)コンテナのログを確認する
kubectl logs [pod-name] -c [container-name] -p
# -p: --previouspodやnodeのリソースの使用率などを確認する
# podを確認
$ kubectl top pod
# nodeを確認
$ kubectl top node
# クラスター内の全てのPodのCPU使用率とメモリ使用量を表示
$ kubectl top pod --all-namespaces --containerstopコマンドを使用するためにはmetrics-serverが必要。(参考)
kubernetes configの確認
$ kubectl config viewkubernetesリソースタイプに関するドキュメントを確認
$ kubectl explain <RESOURCE>
# ex).
$ kubectl explain pods現在のクラスター状態を確認
$ kubectl cluster-info
Kubernetes control plane is running at https://127.0.0.1:58139
CoreDNS is running at https://127.0.0.1:58139/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
# より詳細なクラスター情報を取得
$ kubectl cluster-info dump
...既存のdeploymentのコンテナイメージを更新
ex). deployment/nginxのbusyboxコンテナイメージを「busybox」に設定し、nginxコンテイメージを「nginx:1.9.1」に設定します。
$ kubectl set image deployment/nginx busybox=busybox nginx=nginx:1.9.1既存のdeploymentのスケールを変更
$ kubectl scale deployment nginx-deployment --replicas=3既存のdeploymentに新しい環境変数を追加
$ kubectl set env deployment/nginx-deployment ENV_VAR=productiondeploymentのロールアウト履歴を表示
$ kubectl rollout history deployments nginx-deploymentdeploymentのロールバック
# 1つ前にロールバック
kubectl rollout undo deployment/abc
# revision 3にロールバック
kubectl rollout undo deployment/abc --to-revision=3podのログをリアルタイムで確認
kubectl logs -f <pod_name>
# -f: --followクラスター内のPodに対して特定のラベルが付いているものを削除
$ kubectl delete pods -l app=nginx
$ kubectl delete pods --selector=app=nginx
# -l: --selectorStorage
etcdとraftアルゴリズム
etcdは分散システムでキーと値を保存するための分散型のキーバリューストア。設定情報やサービス検出など、複数のノード間でデータを共有する必要がある場合に利用される。特に、Kubernetesなどのコンテナオーケストレーションプラットフォームで、クラスタの状態管理や設定、オブジェクト(Pod、Service、ConfigMapなど)の情報が格納されている。
etcdはRaftアルゴリズムを使用して、複数のノード間でデータの一貫性を保っています。
┌─────────────────── etcdクラスター ───────────────────┐
│ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ Node A │ │ Node B │ │ Node C │ │
│ │(Leader) │◄──►│(Follower)│◄──►│(Follower)│ │
│ │ │ │ │ │ │ │
│ └─────────┘ └─────────┘ └─────────┘ │
│ │ │ │ │
│ └──────────────┼──────────────┘ │
│ │ │
└──────────────────────┼────────────────────────────┘
│
▼
┌─────────────┐
│ Kubernetes │
│ Cluster │
└─────────────┘etcdクラスターは通常3つまたは5つのノードで構成され、1つのLeaderと複数のFollowerに分かれて動作する。
Raftアルゴリズムの動作原理
1. Leader選出プロセス
Raftアルゴリズムでは、まずクラスター内でLeaderを選出する。
初期状態 → Candidate → Leader
│ │ │
│ ▼ ▼
└── Follower ◄────── Heartbeat- 初期状態: すべてのノードがFollower状態で開始
- Candidate: Leaderが見つからない場合、ノードはCandidate状態になり選挙を開始
- Leader: 過半数の票を獲得したノードがLeaderになる
- Heartbeat: LeaderはFollowerに定期的にHeartbeatを送信して生存を確認
2. ログレプリケーションの流れ
データの書き込みは以下の手順で行われます:
クライアント要求
│
▼
┌─────────┐ 1. ログエントリ ┌─────────┐
│ Leader │ ──────────────► │Follower │
│ │ │ │
│ │ ◄────────────── │ │
└─────────┘ 2. 成功応答 └─────────┘
│
▼
3. コミット確認
│
▼
クライアントに応答- クライアントからの書き込み要求をLeaderが受信
- Leaderがログエントリを作成し、すべてのFollowerに送信
- 過半数のFollowerから成功応答を受信
- Leaderがエントリをコミット
- クライアントに成功を応答
3. 一貫性保証のメカニズム
Raftアルゴリズムの強力な一貫性保証は以下のプロセスで実現されます:
書き込み要求の処理:
Step 1: Leader受信
┌─────────┐
│ Client │ ──write──► ┌─────────┐
└─────────┘ │ Leader │
└─────────┘
Step 2: 過半数レプリケーション
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Leader │───►│Follower │───►│Follower │
│ [Log] │ │ [Log] │ │ [Log] │
└─────────┘ └─────────┘ └─────────┘
│ │ │
└──── 過半数(2/3)の同意 ────┘
Step 3: コミット
┌─────────┐
│ Client │ ◄──success─── ┌─────────┐
└─────────┘ │ Leader │
└─────────┘etcdにおけるRaftの利点
1. 強一貫性(Strong Consistency)
- 過半数の合意メカニズムにより、すべてのノードで同じデータを保証
- 「Split-brain」問題を回避
2. 高可用性(High Availability)
- 単一障害点なし
- 過半数のノードが生きていれば正常に動作継続
- 例:5ノード構成なら2ノードまでの障害に対応可能
3. 自動フェイルオーバー
- Leaderに障害が発生すると自動で新しいLeaderを選出
- ダウンタイムを最小限に抑制
まとめ
etcdとRaftアルゴリズムの組み合わせにより、Kubernetesクラスターは以下を実現しています:
- データの整合性: クラスター内のすべての情報が一貫して管理
- 高い可用性: 部分的な障害があっても継続的なサービス提供
- 自動復旧: 障害からの自動回復メカニズム
この仕組みを理解することで、Kubernetesクラスターの安定性とリライアビリティの源泉を把握でき、より効果的な運用が可能になる。
etcdのrequest limit
1.5MiB
etcdはデフォルトで1つのバリューのサイズは最大1.5MiBまで格納することができる。
これは--max-request-bytesフラグで設定を変更することが可能。
参照
PersistentVolumeとPersistentVolumeClaim
- Volume:
あらかじめ用意されたボリュームを、リソースを作成することなく、マニフェストに直接指定することで利用可能にするもの。
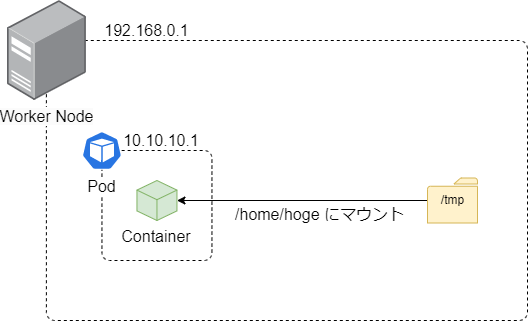
apiVersion: v1 kind: Pod metadata: name: sample-pod spec: containers: - name: nginx-container image: nginx:latest volumeMounts: - name: template-volume mountPath: /home/hoge volumes: - name: template-volume hostPath: path: /tmp type: Directoryspec.volumesには「あらかじめ用意されたボリューム」の情報を記述する。
spec.volumes.hostPathのpathにはノードのパスを指定。typeには指定したパスがディレクトリであることを明示す。spec.containers.volumeMountsにはボリュームのマウントを指定。nameにはマウントしたいspec.volumes.nameを指定する。mountPathにはマウント先のパスを指定。これはコンテナ内部のパス。上記のマニフェストではコンテナが稼働しているノードの/tmpを、コンテナ内部の/home/hogeにマウントする、という意味になる。
- PersistentVolume (PV):
外部の永続ボリュームを提供するシステムと連携して、永続化領域を確保するボリューム。AWSでは外部の永続ボリュームとしてEFSを提供している。
PVは個別にリソースを作成する必要がある。PVはボリュームリソースを表現するだけで、それ自体で何かが出来るわけではない。PVを利用するには、コンテナとPVを結ぶPersistentVolumeClaimが必要になる。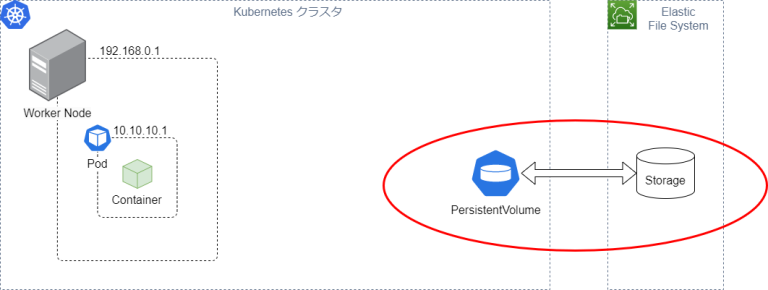
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: efs-sc provisioner: efs.csi.aws.com --- apiVersion: v1 kind: PersistentVolume metadata: name: efs-pv spec: capacity: storage: 5Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain storageClassName: efs-sc csi: driver: efs.csi.aws.com volumeHandle: fs-xxxxxxxxPVを作成する前にStorageClassリソースを作成している。
StorageClassはストレージの種類を記述する。今回であればAWS EFSを利用したストレージとなるので、provisionerにefs.csi.aws.comを指定している。次にPVを作成。
specにPVに関する情報を記述。
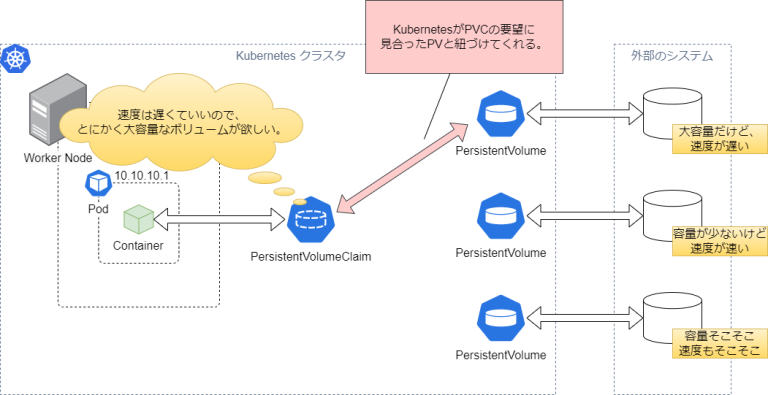
capacity.storageにはそのストレージの容量を記述するが、EFSは容量の上限がないので意味はない。PVでは必須項目となっているため、それっぽい数値を当てている。accessModesはそのボリュームへのマウントについて記述する。ReadWriteManyは、そのボリュームが複数のノードで読み取り/書き込みとしてマウントされることを示す。persistentVolumeReclaimPolicyはそのボリュームの利用が終了したとき(コンテナが停止したなど)、そのボリュームの後処理を指定する。Retainはデータを消さずにそのまま残す、という意味。他にはDeleteがあり、その名の通り、ボリューム利用後はデータを削除する。storageClassNameは先ほど作成したStorageClassの名前を指定する。csiには実際に利用するEFSを指定する。driverはefs.csi.aws.comに固定。volumeHandleはEFSのファイルシステムIDを指定し、これによりPVとEFSのリソースが紐付く。 - PersistentVolumeClaim (PVC):
PVCによりコンテナとPVを紐づける。PVCにはそのコンテナが欲してるボリュームを記述し、これによりKubernetesはコンテナが欲しているボリュームと紐付けてくれる。
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: efs-claim spec: accessModes: - ReadWriteMany storageClassName: efs-sc resources: requests: storage: 5Gispecには要望するボリュームの条件が記述される。上記のマニフェストでは、容量、アクセスモード、StorageClassが条件として記述されている。他にはボリュームに付与されたラベルでも条件指定が可能。実際にマウントしたマニフェストが以下となる。
apiVersion: v1 kind: Pod metadata: name: sample-pod spec: containers: - name: nginx-container image: nginx:latest volumeMounts: - name: persistent-storage mountPath: /home/hoge volumes: - name: persistent-storage persistentVolumeClaim: claimName: efs-claimspec.volumes.persistentVolumeClaim.claimNameには先ほど作成したPVCの名前を指定する。これによりPVCで要望したボリュームがこのコンテナのボリュームとして紐づく。
Ceph
スケーラブルで高パフォーマンスな分散ストレージシステム。分散ストレージなので、ファイルやデータを複数のストレージ(HDDやSSD等)にまたがって保存する。
より特徴的なのが、ファイルが一つのストレージにまとまって保存されるのではなく、分割されて複数のストレージに分散して保存される。この手法は「ストライピング(RAID0)」と呼ばれる。
ストライピングにより、データの読み書きが並列処理で行われるため、I/Oパフォーマンスの向上が見込める。例えば、あるファイルがHDD1台に格納されている場合と、HDD3台に分割して保存されている場合を比較すると、後者の方が各HDDにかかる負荷が分散される。その結果、ストレージ全体でのスループットやIOPSが向上することが期待される。
Rook
Ceph、EdgeFSなどのストレージシステムの展開と管理を自動化する、Kubernetes向けのクラウ
ドネイティブストレージオーケストレーター。Kubernetes環境でストレージリソースを管理するための柔軟でスケーラブルな方法を提供する。
Network
kubernetesのサービスディスカバリー
環境変数とDNSは、Kubernetesクラスター内でのサービスディスカバリーの主要なモード。
ポッドが作成されると、Kubernetesは同じ名前空間で実行されている他のサービスを指す環境変数をポッドのコンテナに自動的に設定。
さらにKubernetesは組み込みのDNSサービスを提供し、ポッドがDNS名を使用して相互に発見・通信することを可能にする。
ServiceとIngress
┌─────────── クラスター外部 ───────────┐
│ │
│ ┌─────────┐ │
│ │ Client │ │
│ └─────────┘ │
│ │ │
└───────┼────────────────────────────┘
│
┌───────▼──── Ingress Layer ─────────┐
│ ┌─────────────────────────────┐ │
│ │ Ingress │ │
│ │ • HTTP/HTTPSルーティング │ │
│ │ • ドメインベースルーティング│ │
│ │ • パスベースルーティング │ │
│ │ • SSL終端 │ │
│ └─────────────────────────────┘ │
└───────┬────────────────────────────┘
│
┌───────▼──── Service Layer ─────────┐
│ │
│ ┌─────────┐ ┌─────────┐ │
│ │Service A│ │Service B│ │
│ │• 負荷分散 │ │• 負荷分散 │ │
│ │• サービス │ │• サービス │ │
│ │ディスカバリ│ │ディスカバリ│ │
│ └─────────┘ └─────────┘ │
└───────┬────────┬───────────────────┘
│ │
┌───────▼────┐ ┌─▼──────┐
│ Pod A1 │ │ Pod B1 │
│ Pod A2 │ │ Pod B2 │
└────────────┘ └────────┘主な違い
| 項目 | Service | Ingress |
|---|---|---|
| 役割 | L4負荷分散 | L7ルーティング |
| 対象 | クラスター内外 | クラスター外→内 |
| プロトコル | TCP/UDP | HTTP/HTTPS |
| 機能 | 基本的な負荷分散 | 高度なルーティング |
Serviceの種類と用途
- ClusterIP (デフォルト):
- クラスター内のみアクセス
- 内部サービス間通信
- NodePort:
- 各ノードのポートで公開
- 簡易的な外部アクセス
- LoadBalancer:
- クラウドのLB利用
- 本格的な外部公開
実際の使い分け
- Service単体での外部公開
Internet → LoadBalancer Service → Pod
- 適用場面: 単一サービス、TCP/UDP通信
- 制限: ドメインルーティング不可
- Ingress + Serviceの組み合わせ
Internet → Ingress Controller → Service → Pod
- 適用場面: 複数サービス、HTTP/HTTPS
- 利点: ドメイン・パスベースルーティング、SSL終端
具体例
# Service例
apiVersion: v1
kind: Service
metadata:
name: web-service
spec:
selector:
app: web
ports:
- port: 80
targetPort: 8080
---
# Ingress例
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: web-ingress
spec:
rules:
- host: example.com
http:
paths:
- path: /api
backend:
service:
name: api-service
- path: /web
backend:
service:
name: web-serviceまとめ
ServiceはPodへの基本的なアクセスを提供し、IngressはHTTP/HTTPSの高度なルーティングを担当する。両者を組み合わせることで柔軟なトラフィック制御を実現。
Headless Service
Podを外部に直接公開することなく、DNS名を使ってPodにアクセスできるようにする。Headless
Serviceを作成することで、StatefulSetによって管理されるPodに対して一貫したDNS命名を実現でき、各Podが一意で予測可能なDNS名を持つことが保証される。
例
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: myapp
spec:
serviceName: headless-service
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: nginx-container
image: nginx:1.12
---
apiVersion: v1
kind: Service
metadata:
name: headless-service
spec:
clusterIP: None # <------ これが headless service に必須の設定
ports:
- name: "http-port"
port: 80
targetPort: 80
selector:
app: myapp <pod-name>.<service-name>.<namespace-name>.svc.cluster.localでpodの名前解決が可能。
# Headless Serviceの名前解決を確認
dig a +short headless-service.default.svc.cluster.local
10.244.0.5
10.244.0.6
10.244.0.7
# PodのIPアドレスの名前解決を確認
dig a +short myapp-0.headless-service.default.svc.cluster.local
10.244.0.5EndpointsとEndpointSlice
- Endpoints:
- Endpoints(kind: Endpoints) は、対応する Service を支える Pod の IP アドレスとポートを列挙するオブジェクト。
- kubectl get endpoints や kubectl describe endpoints で確認できる。
- IP アドレスとポートの詳細を含む subsets 配列を持つ。
- 制御プレーンが自動管理し、通常はユーザーが直接触ることは少ない。
Endpointsの課題
- スケーラビリティ
- 大規模な環境では、1つの Service が数百〜数千もの Pod を抱える場合がある
- Endpoints オブジェクトが巨大化し、Pod の増減のたびに大きなオブジェクトを更新する必要がある
- APIサーバーの負荷増大
- kube-proxy は API サーバーと watch で接続し、Endpoints の更新を受け取る
- 巨大な Endpoints を頻繁にやり取りすると、API サーバー側の通信量・CPU 使用率が大きくなる
- 部分更新のしにくさ
- Pod の状態が1つ変わっただけでも、Endpoints 全体を更新する必要があり、効率が悪い
こうした問題を解決するために開発されたのが EndpointSlice
(Endpoinstは現在ではdeprecatedとなっており、EndpointSliceを使用するようになっている) - EndpointSlice:
EndpointSlice導入の背景
- Kubernetes 1.16 でアルファ版として導入され、1.19 以降ではデフォルトで有効化。
- 単一の巨大な Endpoints オブジェクトにすべての Pod 情報を入れる非効率を解消するために設計された。
EndpointSliceの特徴とメリット
- 分割管理
- Pod 情報を複数の EndpointSlice リソースに分散。
- 1 つの EndpointSlice には最大100件(デフォルト)のエンドポイントを含めるなど、オブジェクトサイズを制限できる。
- 更新効率の向上
- 変更のあった Slice だけを更新するため、Pod の増減が頻繁でも不要な大規模リソース書き換えが起きにくい。
- 豊富なメタデータ
- nodeName、zone、ready / serving / terminating 状態などを持ち、トポロジーを意識した高度なルーティングを可能にする。
- サービスとの自動連携
- Endpoints と同様に Service コントローラーが自動生成・更新を行い、ユーザーが直接管理する必要はほぼない。
Service、Endpoint / EndpointSlice、kube-proxyの関係
- Service: 安定したアクセス先として IP / DNS を提供し、Pod グループへ負荷分散を行う。
- Endpoint / EndpointSlice: Serviceの裏側で実際にトラフィックを受け取る Pod の IP / ポート情報を管理する。
# <service-name>のendpointsliceを確認 kubectl get endpointslice -l kubernetes.io/service-name=<service-name> - kube-proxy: 各 Node に配置され、EndpointSlice などの更新を反映しながらネットワーク転送ルールを動的に設定する。
Envoy
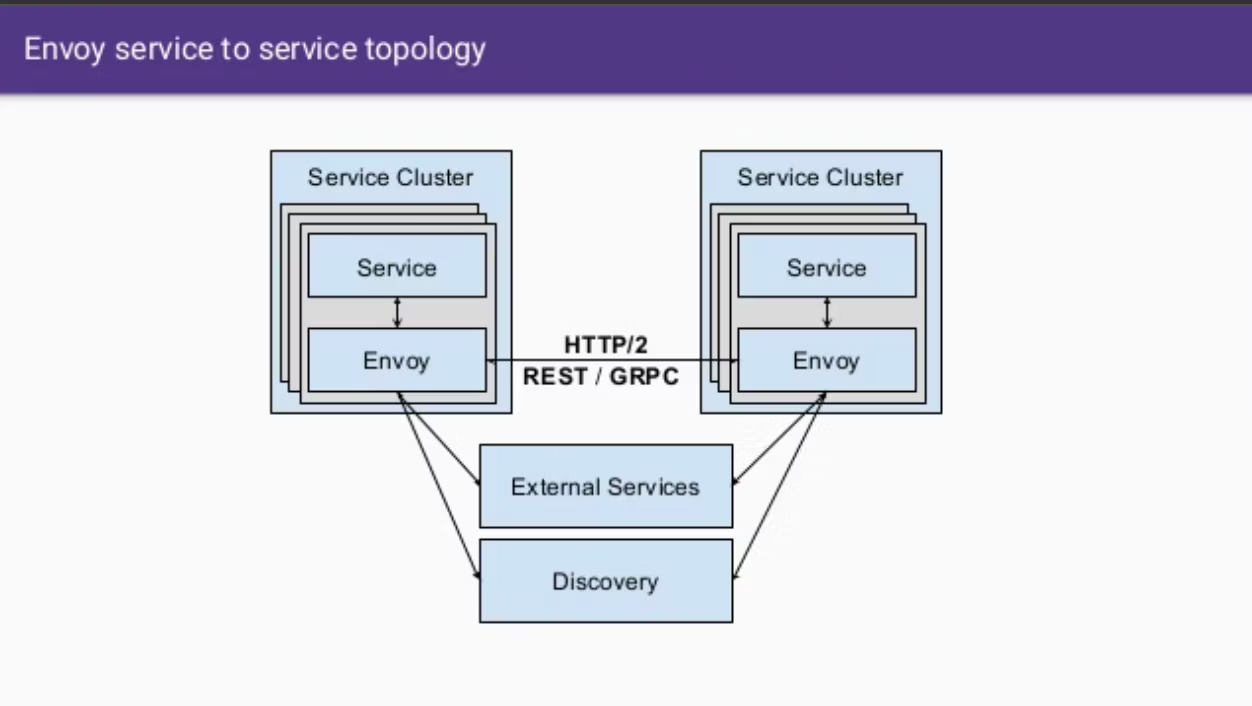
マイクロサービス間のトラフィック管理を処理するように設計された、広く使用されているオープンソースの軽量プロキシ。サービスディスカバリ、ロードバランシング、サーキットブレーカーなどの機能を提供し、マイクロサービス間の通信管理を担う。
Kubernetesなどでは、Envoyを各アプリケーションのサイドカーコンテナとしてデプロイし、これにより、各サービスは別のサービスを直接参照するのではなくEnvoyを経由することになる。
Istio
Istioは、Kubernetesでマイクロサービス間の通信を管理するサービスメッシュプラットフォーム。
基本アーキテクチャ
┌─────────── Control Plane ───────────┐
│ ┌─────────┐ ┌─────────┐ ┌───────┐ │
│ │ Pilot │ │ Galley │ │Citadel│ │
│ │(ルーティ │ │ (設定) │ │(証明書)│ │
│ │ング制御) │ │ │ │ │ │
│ └─────────┘ └─────────┘ └───────┘ │
└─────────────────┬───────────────────────┘
│
┌─────────────────┴── Data Plane ──────┐
│ │
│ ┌── Service A ──┐ ┌── Service B ──┐ │
│ │ ┌─────────┐ │ │ ┌─────────┐ │ │
│ │ │ App │ │ │ │ App │ │ │
│ │ └─────────┘ │ │ └─────────┘ │ │
│ │ ┌─────────┐ │ │ ┌─────────┐ │ │
│ │ │ Envoy │◄─┼──┼─►│ Envoy │ │ │
│ │ │Sidecar │ │ │ │Sidecar │ │ │
│ │ └─────────┘ │ │ └─────────┘ │ │
│ └───────────────┘ └───────────────┘ │
└──────────────────────────────────────┘Sidecarパターン
┌─────── Pod ───────┐
│ ┌─────────────┐ │
│ │ App │ │
│ └─────────────┘ │
│ │ │
│ ┌─────────────┐ │ ◄─── 外部通信
│ │ Envoy │ │
│ │ Sidecar │ │
│ │• 負荷分散 │ │
│ │• 暗号化 │ │
│ │• メトリクス │ │
│ └─────────────┘ │
└───────────────────┘主要機能
- トラフィック管理
Gateway → Virtual Service → Destination Rule → Pod
↓ ↓ ↓
外部入口 ルーティング 負荷分散制御2. セキュリティ(mTLS)
Pod A ◄──暗号化通信──► Pod B
│ │
└─── Citadel証明書 ────┘3. 可観測性
┌─ Metrics ─┐ ┌─ Tracing ─┐ ┌─ Logs ─┐
│• リクエスト数│ │• 分散追跡 │ │• アクセス│
│• エラー率 │ │• 依存関係 │ │• 監査 │
│• レスポンス │ │• ボトルネック│ │• デバッグ│
└───────────┘ └──────────┘ └────────┘主な利点
- 非侵入型: アプリコードを変更せずに機能追加
- 統一管理: 全サービス間通信を一元制御
- 高機能: カナリアデプロイ、A/Bテスト、自動mTLS
Istioにより、マイクロサービス環境でのセキュリティ・可観測性・トラフィック制御を簡単に実現できる。
Linkerd
kubernetes 用のサービスメッシュではIstioが有名だが、Linkerd もCNCFの Graduate project となっているためプロジェクトの成熟度は高く使用ユーザーも多い。
Linkerd は各 pod に proxy の役割を果たす proxy コンテナを inject し、proxy コンテナが Linkerd の control plane と通信することでサービスメッシュを実現する(lstio における envoy と同じような感じ)。
Linkerd では接続対象のクラスタの k8s service リソースを接続元のクラスタに複製し、この複製されたサービスを経由して接続先クラスタにアクセスする構成によりクラスタ間の通信を実現(ドキュメントでは mirroring や service mirror 等と呼ばれている)。
複製されたサービスの通信先は対象クラスタ上に存在する外部アクセス可能な Gateway となっており、これを経由して対象の svc, pod に接続しに行く。
そしてこの通信を制御するのが Linkerd の micro proxy コンテナ (Linkerd-proxy) となる。
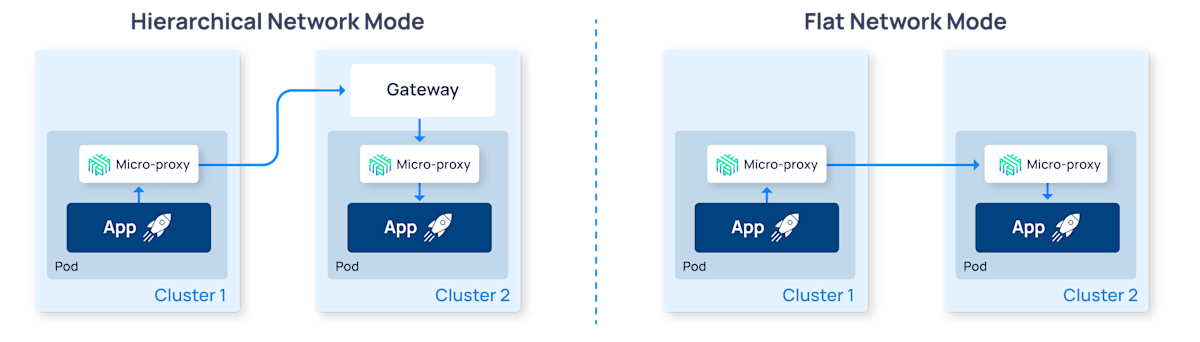
Linkerd ではこのような Gateway を経由してクラスタ間通信を実現する Hierarchical Network mode と、 gateway を使用せずクラスタの POD 間で直接通信を行う Flat Network mode (Pod-to-Pod 通信) がサポートされている。
CoreDNS
Kubernetes 1.13以降でデフォルトのDNSサーバーとして採用されているクラウドネイティブなDNSサーバーで、以前のkube-dnsを置き換えている。
Kubernetesクラスター内でのサービスディスカバリを担当し、ServiceやPodに対するDNS名前解決を提供してアプリケーション間の通信を可能にする。プラグインベースのアーキテクチャを採用し、設定ファイル(Corefile)によって柔軟にDNS動作をカスタマイズでき、ログ、メトリクス、キャッシュ、フォワーディングなどの機能を組み合わせられる。
通常kube-system名前空間にDeploymentとして動作し、クラスター内のDNSクエリを処理してKubernetesのサービスメッシュ機能を支える重要なコンポーネント。CNCFのGraduatedプロジェクトとして高いパフォーマンスと拡張性を提供し、マイクロサービス環境でのサービス間通信の基盤となっている。
Kindで起動したKubernetesクラスターを見てみると、以下のようにCoreDNSが使用されているのがわかる。
$ kubectl get deployments -n kube-system -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
coredns 2/2 2 2 2d20h coredns registry.k8s.io/coredns/coredns:v1.12.0 k8s-app=kube-dnsContainer Network Interface (CNI)
コンテナ環境でネットワーク接続を管理するための標準仕様。コンテナにIPアドレスを割り当てたり、ネットワークを構築したりするための仕組みを提供する。
CNI自体は「仕様」であり、実際のネットワーク構成はCNIプラグインと呼ばれるツールによって実現される。これにより、コンテナオーケストレーションツール(Kubernetesなど)はCNIを通じてネットワークを簡単に管理できるようになる。
CNIは、以下のようにコンテナのネットワークを管理する:
- コンテナの起動時:
CNIプラグインが呼び出され、IPアドレスやルーティング情報を割り当てる。
必要に応じて仮想ネットワークインターフェース(veth)やブリッジを作成。 - コンテナの終了時:
ネットワークリソースを解放し、IPアドレスを再利用可能な状態に戻す。
CNIは以下の2つのコマンドを利用して動作する:
- ADD: ネットワークを追加する(例: IPアドレスの割り当て)。
- DEL: ネットワークを削除する(例: IPアドレスの解放)。
この様にCNIは「ネットワーク専属の管理者」のような役割を果たす。
ADDコマンドは、「新しい社員がオフィスに来たときに、デスク(ネットワーク接続)を用意する管理者」。
→ 例えば、「社員AにIPアドレス192.168.1.10を割り当てて、このデスク(コンテナ)を他のデスクと通信できるようにする」といった作業をする。
DELコマンドは、「退職した社員のデスクを片付ける管理者」。
→ 例えば、「社員Aのデスクを撤去して、そのIPアドレスを次の社員が使えるようにする」といった作業をする。
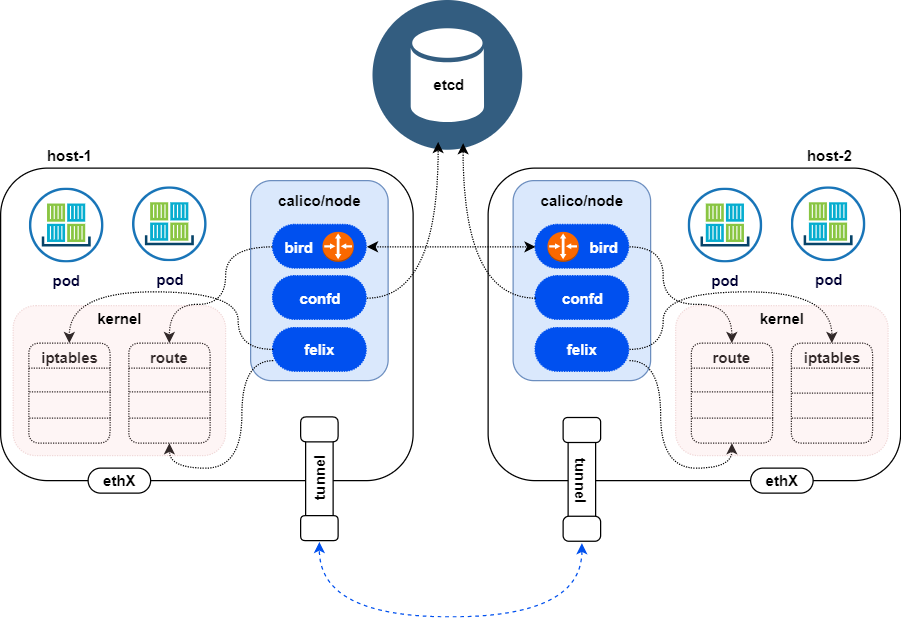
Calico
コンテナと仮想マシン向けのオープンソースネットワーキングプロジェクトで、OSIモデルのレイヤー3(ネットワーク層)上に構築されている。
BGP(Border Gateway Protocol)を使用してノード間のルーティングテーブルを構築し、高いパフォーマンスとネットワーク分離を実現する。Kubernetes CNI(Container Network Interface)プラグインとして実装され、フラットなレイヤー3ネットワークを作成してすべてのポッドにルーティング可能なIPアドレスを割り当てる。デフォルトでクラスター内の全ノード間にBGPメッシュを作成し、各ノードがレイヤー3ゲートウェイとして機能してコンテナーネットワークの経路を他のワーカーノードにブロードキャストする。
Kubernetes 仮想クラスターネットワーク
Dockerコンテナネットワーク
Kubernetesコンテナネットワークに焦点を当てる前に、Dockerコンテナネットワークの構成を整理。(※ここでは、もっともスタンダードなBridge形式について説明。)
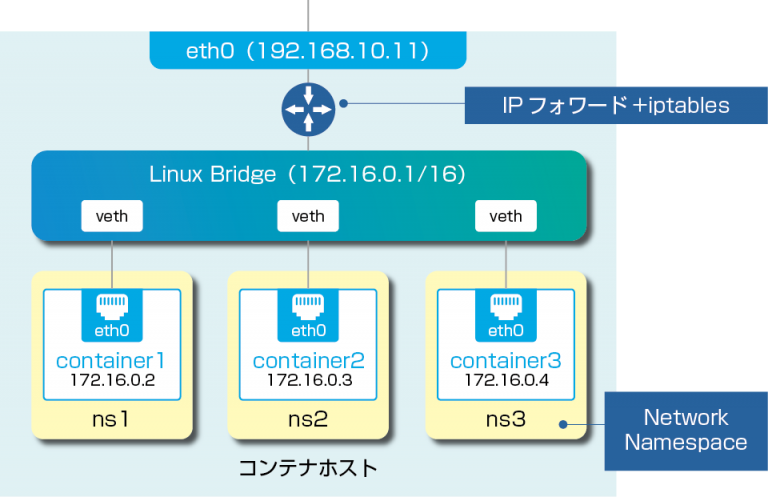
- 仮想ブリッジ: Dockerコンテナ同士をつなぐための仮想的なブリッジ。
物理L2スイッチと同じ振る舞いをする。Dockerの場合、「docker0」という名前で登場。 - veth(Virtual Ethernet Device): 仮想ネットワークインターフェース(仮想NIC)のこと。
vethは必ずペア(veth、veth peer)で作成され、ペア間で通信が可能となる。
(上の図でいうと、Linux Bridgeにある各vethと各コンテナのeth0がペアとなっている。) - Network Namespace(netns、ネットワーク名前空間): Linuxは、カーネルが扱うリソースを独立した単位でまとめて、OSから隔離させる機能を擁してい。(つまり、コンテナをOSから隔離させるために必要な技術)この機能をNetwork Namespace(netns)と呼びぶ。
分離されたリソースは、同一のnetnsに属するプロセス以外からは直接見えない。 - iptables: Linuxのパケットフィルター。ファイアウォール、NAT(SNAT、DNAT、Masquerade)等の機能が提供されている。
2つのvethペアそれぞれにおいて、片方のvethを作成したnetnsに組み込み、もう片方を仮想ブリッジ側のインターフェースとすることで、2vethペアでnetns同士(ひいてはコンテナ同士)をつなぐことができる。ちなみに、コンテナ内からは、vethは「eth0」という名前の仮想NICとして見える。
コンテナがホスト外部と通信する場合には、iptablesによる「NAT(グローバルIPアドレスとプライベートIPアドレスを変換する仕組み)」が利用される。
Kubernetesコンテナネットワーク
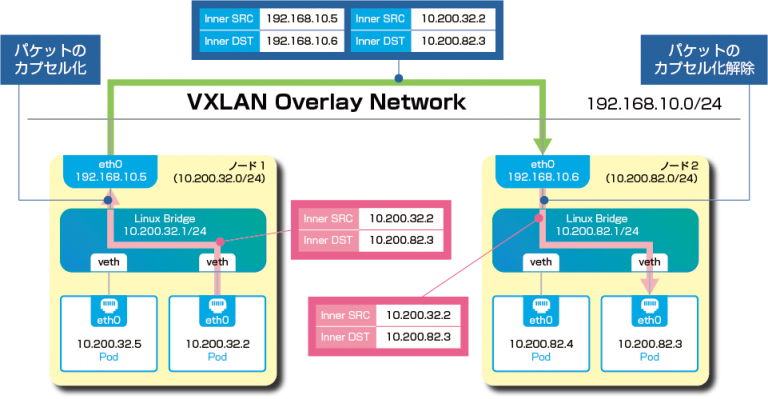
Kubernetes環境下の場合、基本的にクラスタ環境が構築される。そのため、Kubernetesが扱う最小単位であるPod間の通信に課題が残る。
各PodにはIPアドレスが割り振られるが、Pod同士の通信が可能なのは同一Node内のみであって、そのままのIPアドレスでNodeをまたいだ通信を行うのは困難。
Dockerでは、コンテナとホスト外部の通信にはNATが利用される。しかし、たとえばAP用ホストとDB用ホストを分ける場合など、毎回NATテーブルを操作するのは、管理の面から見て現実的ではない。
そこで採用されるのが、VXLAN技術による「オーバーレイネットワーク」。オーバーレイネットワークとは、一言でいえば、あるネットワークの上に構築された別のネットワークを指す。Pod間通信においては、以下のような流れでオーバーレイネットワークを介して、各Podが連携されてる。
- Podからパケットが送信される
- 送信されたパケットは、Node内のブリッジを経由してLinuxカーネルでカプセル化。オーバーレイネットワークを経由して、宛先Nodeに向かう
- 宛先Node内にてカプセル化が解除され、受信側のPodにパケットが届く
このように、Node間でオーバーレイネットワークを構成することで、クラスタ環境におけるPod間通信を実現させる。
この様なネットワークをより簡単に行うためのプロジェクトとしてCalicoなどがあり、CNIという標準に準拠しているAPIを提供している。
Security
Security ContextsとSecurity Policies (Like PodSecurityPolicies or Kyverno)のスコープの違い
Security Contextはコンテナランタイムレベルで動作し、Security Policyはクラスター制御プレーンレベルで動作する。
Security Contextは、実行中にコンテナやPodの特定のセキュリティ属性を定義するために利用され、ノード内でどのように実行されるかに直接影響を与える。
一方、Security Policy(PodSecurityPolicyやKyvernoなど)は、より高いレベルで動作し、クラスター全体でのPod作成と動作に関して何が許可されるかを統制するルールを定義し、個々のコンテナランタイム設定ではなく制御プレーンレベルでセキュリティ標準を強制する。
KubernetesがセキュリティコンテキストPod Security Policieの両方をサポートしている理由は、セキュリティコンテキストが本来Pod Security Policiesの代替品であるため。Pod Security Policiesを使用すれば、クラスター内で実行されているすべてのポッドの権限を構成できるが、個々のポッドに適用できるセキュリティコンテキストの方が細かい制御が可能。
Kubernetes バージョン1.21では、Pod Security Policiesは非推奨とされ、Kubernetes 1.25で完全に削除された。定義済みのPod Security Policiesはその時点で無視されることになる。
KubeScape
ARMO が提供しているオープンソースの Kubernetes のセキュリティープラットフォームで、 IDE, CI/CD pipelines, Kubernetesクラスタ, CLI などさまざま場所で容易に実行できるのが特徴。開発中のローカルマシン上 ~ 本番の Kubernetesクラスタ 上といった任意の箇所で実行でき、実行結果は様々なフォーマットで出力可能。
また、Kubernetes クラスタ, YAMLファイル, Helm charts を検出対象として選択でき、これらの中からミスコンフィグレーションを複数のフレームワークを用いて (NSA-CISA, MITRE ATT&CK®, CIS Benchmark) 検出することが可能。
Falco
Kubernetes 内のコンテナやPodにおける異常な活動のランタイムセキュリティ監視と検出を行う。
クラウドネイティブなオープンソースのセキュリティツール。
システムコールを使用してコンテナの活動を監視し、特権昇格や不正アクセスなどの異常な動作を検出できる。
X.509証明書
公開鍵基盤(PKI)においてデジタル身元を証明するための標準形式。インターネット通信の安全性確保に広く使用される。
┌─────────────────┐ 証明 ┌─────────────────┐
│ 証明機関(CA) │ ────────→ │ エンティティ │
└─────────────────┘ └─────────────────┘
│ │
└── 証明書を発行 ──────────────┘証明書の構造
┌──────────────────────────────────────┐
│ X.509証明書 │
├──────────────────────────────────────┤
│ Version (バージョン) │
│ Serial Number (シリアル番号) │
│ Signature Algorithm (署名アルゴリズム)│
│ Issuer (発行者) │
│ Validity Period (有効期間) │
│ Subject (主体者) │
│ Subject Public Key Info (公開鍵情報) │
│ Extensions (拡張領域) │
│ Certificate Signature (証明書署名) │
└──────────────────────────────────────┘主要フィールド:
- Subject: 証明書所有者の識別名(DN)
- Issuer: 発行した認証機関の識別名
- Public Key: 暗号化・署名検証用公開鍵
- Validity Period: 証明書の有効期間
- Extensions: 追加属性(SAN、キー用途等)
PKI階層構造
┌─────────────────┐
│ Root CA │ ← 最上位認証機関(自己署名)
└─────────┬───────┘
│ 署名
┌─────────▼───────┐
│ Intermediate CA │ ← 中間認証機関
└─────────┬───────┘
│ 署名
┌─────────▼───────┐
│ End Entity │ ← エンドエンティティ(実際のサービス)
└─────────────────┘CSR(Certificate Signing Request)から証明書発行まで
申請者 認証機関(CA)
│ 1. 鍵ペア生成 │
│ 2. CSR作成 │
│ 3. CSR送信 ──────────→ │
│ │ 4. 身元確認・検証
│ │ 5. 証明書生成・署名
│ ←──────────── 6. 証明書送信 │
│ 7. 証明書導入・確認 │実用コマンド
# 秘密鍵生成
openssl genrsa -out private.key 2048
# CSR作成
openssl req -new -key private.key -out request.csr \\
-subj "/C=JP/ST=Tokyo/O=Company/CN=example.com"
# 証明書確認
openssl x509 -in certificate.crt -text -nooutクライアント側検証プロセス
HTTPS接続での検証フロー
クライアント サーバー
│ 1. TLS Handshake開始 │
├────────────────────────────────────→│
│ 2. 証明書チェーン送信 │
│←────────────────────────────────────┤
│ 3. 証明書検証プロセス │
├─ ① チェーン構築 │
├─ ② 署名検証 │
├─ ③ 有効期間確認 │
├─ ④ 失効確認 (CRL/OCSP) │
├─ ⑤ ホスト名検証 │
└─ ⑥ 用途確認 │
│ 4. 検証成功 → 安全な通信開始 │
検証項目詳細
署名検証: 各証明書がその発行者の秘密鍵で正しく署名されているか
有効期間: 現在時刻が Not Before ≤ 現在時刻 ≤ Not After の範囲内か
失効確認: CRL(証明書失効リスト)またはOCSPで失効状態を確認
ホスト名検証: 証明書のSAN(Subject Alternative Names)またはCNが接続先ホスト名と一致するか
実際の使用例
主要用途
- HTTPS: Webサーバー認証
- コード署名: ソフトウェア完全性確認
- メール暗号化: S/MIME署名・暗号化
- VPN: クライアント/サーバー認証
- Kubernetes: Pod間通信・API認証
証明書の種類
- DV証明書: ドメイン所有確認のみ
- OV証明書: 組織実在確認あり
- EV証明書: 厳格な組織確認
証明書確認
ブラウザでの確認
- Chrome/Edge: アドレスバーの🔒アイコン → 証明書(有効)
- Firefox: 🔒アイコン → 詳細を表示
OpenSSLコマンド
# サーバー証明書確認
openssl s_client -connect example.com:443 -servername example.com
# 証明書チェーン確認
openssl s_client -connect example.com:443 -showcerts
# 有効期限確認
echo | openssl s_client -connect example.com:443 2>/dev/null | \\
openssl x509 -noout -datesKubernetesでの証明書の役割
KubernetesクラスターではX.509証明書が多方面で使用され、セキュアな通信とアクセス制御を実現する。
┌─────────────────────────────────────────────────────┐
│ Kubernetesクラスター │
├─────────────────────────────────────────────────────┤
│ │
│ ┌──────────────┐ mTLS通信 ┌──────────────┐ │
│ │ API Server │ ←─────────────→ │ etcd │ │
│ └──────────────┘ └──────────────┘ │
│ ↑ ↑ │
│ TLS証明書 TLS証明書 │
│ │ │ │
│ ┌──────▼──────┐ ┌───────▼──────┐ │
│ │ kubelet │ │ Controller │ │
│ │ │ │ Manager │ │
│ └─────────────┘ └──────────────┘ │
│ ↑ ↑ │
│ クライアント証明書 クライアント証明書 │
└─────────────────────────────────────────────────────┘Log & Monitoring
分散トレーシングにおけるTraceとSpan
- Trace: リクエストの一連の流れを示す。
- Span: Traceの構成要素で特定の処理(特定のリクエストやトランザクションが処理される間の時間やプロセスの流れ)を示す。
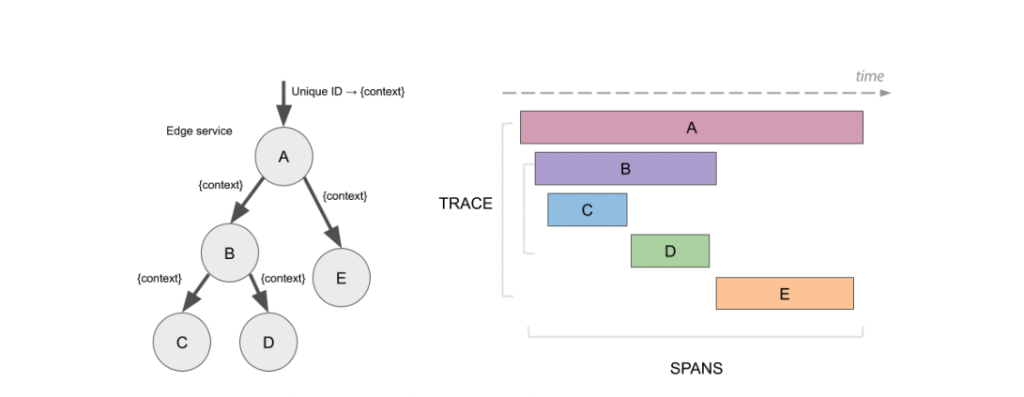
分散トレーシングのOSSであるJeagerで収集したデータの可視化イメージ
左側のグラフのように、取得したデータからサービス間の連携状況を可視化したり、右側のウォータフォールチャートのように、ユーザのリクエストから発生する一連の処理について、どのサービスでどの程度の時間が掛かっているかや、処理実施時のパラメータ情報やエラー発生時のエラーログなどをトランザクション毎に確認できる。これらの可視化機能により、システム全体のパフォーマンスや問題の特定が容易になる。
PrometheusとKibana
PrometheusとKibanaは、両方ともクラウドネイティブ環境で使用されるツールですが、それぞれ異なる役割を果たします。Prometheusはシステムの監視とアラートのためのツールであり、Kibanaはログの可視化と分析を行うためのツールです
- Prometheus:
サーバーのメトリクス(CPU使用率、メモリ使用率など)やアプリケーションのカスタムメトリクスを収集し、それらのデータを保存して、必要に応じてアラートを発生させることができる。 - Kibana:
ログデータを収集し、視覚化して分析するためのツール。ログは、アプリケーションやシステムの動作やイベントに関する情報を提供する。Kibanaを使用すると、ログデータをダッシュボードやグラフなどの視覚化ツールで表示し、パターンやトレンドを分析することができる。
これにより、システムの問題を早期に検知し、問題の特定やトラブルシューティングが容易になる。
PrometheusのCounter, Gauge, Summary, Histgram
- カウンター (Counter):
増加のみを記録するメトリクス。例えばリクエスト数やエラー数など、時間の経過とともに増えていく値を追跡するのに適している。減少はしない。
例:あるエンドポイントへのリクエスト数、あるサービスの起動回数など。
- ゲージ (Gauge):
増加と減少の両方を記録するメトリクス。例えば、CPU使用率、メモリ使用量、温度など、値が上下するものを追跡するのに適している。
例:現在の温度、CPU使用率、キューの長さなど。
- ヒストグラム (Histogram):
観測された値を複数のバケットに分割し、それぞれのバケットに属するデータの個数をカウントする。
通常は、リクエストの処理時間や応答サイズなどの分布を把握するために使用される。平均値や合計値も計算できる。例:リクエストの処理時間(10ms未満、10ms-20ms、20ms-50msなど、バケットを定義)、応答サイズなど。
- サマリー (Summary):
ヒストグラムと同様に、観測された値をサンプリングし、構成可能なバケットでカウントする。
さらに、指定したパーセンタイル(例えば、90パーセンタイル、95パーセンタイルなど)の値を計算し、より詳細なデータ表現を提供する。例:リクエストの処理時間(90パーセンタイル、95パーセンタイルなどの値を計算)など。
まとめ:
- カウンターは増加のみを記録、ゲージは増減を記録。
- ヒストグラムは分布を把握、サマリーはパーセンタイルを計算。
Fluentd
オープンソースのデータ収集・転送ツールで、ログやメトリクスなどの様々なデータソースから情報を収集できる。
プラグインベースのアーキテクチャを採用しており、500以上のプラグインが利用可能で、多様なデータソースや出力先に対応している。
Kubernetesクラスター内では、DaemonSetとして各ノードにデプロイされ、コンテナログを収集してElasticsearch、S3、BigQueryなどの外部システムに転送する役割を果たす。統一されたログ基盤の構築により、マイクロサービス環境での分散ログ管理とリアルタイムデータパイプラインを実現する。
Datadog
Datadog はクラウド アプリケーションのための モニタリングとセキュリティプラットフォーム。Datadog の SaaS プラットフォームは、インフラストラクチャ監視、 アプリケーションパフォーマンス監視、ログ管理を統合および自動化して、テクノロジースタック全体を一元的にリアルタイ ムで監視できるようにする。
Management & Governance
Harbor
コンテナイメージを保存、管理、配布するためのオープンソースのプライベートコンテナレジストリ。VMwareによって開発され、その後世界最大級のオープンソースプロジェクトとされるCNCFに引き継がれた。
DockerイメージやHelmチャートの保存・バージョン管理を提供する。脆弱性スキャン、RBAC、イメージ署名などの高度なセキュリティ機能と、レプリケーション、ガベージコレクション、Web
UI管理などの運用機能を備えている。
CNCFプロジェクトとして他のクラウドネイティブ技術との連携が考慮され、組織内でのプライベートなコンテナイメージ管理を実現する。機密性の高いイメージ管理、複数Kubernetesクラスタでの共有利用、DevOps環境構築、独自コンテナイメージの安全管理などのケースで特に有用。Docker
Hubなどのパブリックレジストリの代替として、セキュアで統制されたコンテナ配布基盤を提供し、企業での利用に適している。
Open Policy Agent(OPA)
統一されたポリシー言語「Rego」を使用してセキュリティ・コンプライアンス・ガバナンスのポリシ
ーを定義・実行するオープンソースのポリシーエンジン。
Kubernetesにおいては、Admission Controllerとして動作し、リソース作成時のセキュリティ制約、リソース制限、コンプライアンス要件などを自動的にチェックして制御する。
アプリケーションコードからポリシーロジックを分離し、宣言的にポリシーを記述できるため、セキュリティ要件の変更に対して柔軟に対応可能。マイクロサービス、API Gateway、CI/CDパイプ
ラインなど様々な場面で利用でき、一貫したポリシー管理を実現する。
CNCFのGraduated プロジェクトとして、クラウドネイティブ環境でのポリシー駆動型セキュリティのデファクトスタンダードとなっている。
Gatekeeper
Kubernetes クラスタにおける Pod の作成、更新リクエストを検証するためのアドミッション コントローラであり、Open Policy Agent(OPA)を使用している。
Gatekeeper を使用すると、管理者は制約を使ってポリシーを定義できる。制約は、Kubernetes でのデプロイの動作を許可または拒否する一連の条件。その後、ConstraintTemplate を使用してクラスタにこのポリシーを適用できる。
Gatekeeper は、以下のことを行う。
- ポリシーのロールアウト: 段階的に範囲を限定してポリシーを適用し、ワークロードの中断のリスクを抑える。
- テスト時のポリシーの変更: ポリシー適用前の影響と範囲をテストするためのメカニズムを提供する。
- 既存のポリシーの監査: 新しいワークロードと既存のワークロードにセキュリティ管理の適用(監査制御)を行う。
Knowledge
kubeadm
kubeadmは、kubeadm initやkubeadm joinなどのコマンドを提供するツールで、Kubernetesクラスターを構築する上でのベストプラクティスを反映した「近道」を提供するものとして開発された。
kubeadmは実用最小限のクラスターをセットアップするための処理を実行する。設計上、kubeadmはブートストラップのみを行い、マシンのプロビジョニングは行わない。同様に、Kubernetesダッシュボード、モニタリングソリューション、クラウド向けのアドオンなど、あれば便利でもなくても支障のない各種アドオンのインストールも範囲外。
その代わりに、高度な特定用途向けのツールはkubeadmをベースに構築されることが期待されている。理想的にはすべてのデプロイのベースとしてkubeadmを使用することで、適合テストに通るクラスターを簡単に作れるようになる。

k3s
Rancher Labsが開発した軽量なKubernetesディストリビューションで、バイナリサイズが約40MBと非常にコンパクト。
1つのコマンドで簡単にインストールでき、512MB程度のメモリで動作するため、IoTデバイスやエッジコンピューティングの開発・学習環境に最適。
TraefikやFlannelなどの必要なコンポーネントが内蔵されており、通常のKubernetesと比べて大幅にセットアップが簡素化されている。
CloudEvents
イベントデータを一般的な方法で記述するための仕様です。この仕様は、Cloud Native Computing Foundation(CNCF)の Serverless Working Group によって編成されたオープン標準仕様。
ex). JSON 形式のペイロード
| 属性 | 説明 | 例 |
|---|---|---|
| data | イベントデータのペイロード。 | { |
| datacontenttype | 渡されたデータの種類 | application/json |
| id | イベントの固有識別子 | 2070443601311540 |
| source | イベントのソース | //pubsub.googleapis.com/projects/my-project/topics/my-topic |
| specversion | このイベントに使用された CloudEvents 仕様のバージョン | 1.0 |
| type | イベントデータのタイプ | google.cloud.pubsub.topic.v1.messagePublished |
| time | RFC 3339 形式のイベントの生成時間(省略可) | 2020-12-20T13:37:33.647Z |
{
"data":{ EVENT_DATA },
"datacontenttype": "application/json",
"id": "MESSAGE_ID",
"source": "//storage.googleapis.com/projects/_/buckets/BUCKET_NAME",
"specversion": "1.0",
"type": "google.cloud.storage.object.v1.finalized",
"time": "EVENT_GENERATION_TIME",
"subject": "objects/my-file.txt"
}Dockerのマルチステージビルド
Dockerfile 中の命令ごとにイメージにレイヤーを追加するため、次のレイヤーへと移る前に、不要なアーティファクト(構築処理によって作成されたイメージ等)を忘れずクリーンアップし続ける必要がある。効率的な Dockerfile を書くためには、以降のレイヤーで必要になるアーティファクトのみを保持するために、シェル(shell tricks)を駆使する必要と、レイヤーを維持するロジックを用いる必要があった。
マルチステージビルドを行うことで以下様に必要なものののみを次のステージにcopyすることが可能。
# syntax=docker/dockerfile:1
# 1st stage を "builder" と名づける
FROM golang:1.16 AS builder
WORKDIR /go/src/github.com/alexellis/href-counter/
RUN go get -d -v golang.org/x/net/html
# 必要なアーティファクトのみをコピー
COPY app.go ./
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
FROM alpine:latest
RUN apk --no-cache add ca-certificates
WORKDIR /root/
# "builder" stageのアーティファクトをコピー
COPY /go/src/github.com/alexellis/href-counter/app ./
CMD ["./app"]サーキットブレーカー
マイクロサービスアーキテクチャにおいて広く採用されているパターンの1つ。2つのサービスの間に配置し、障害状況を監視しながらリクエストを制御する。
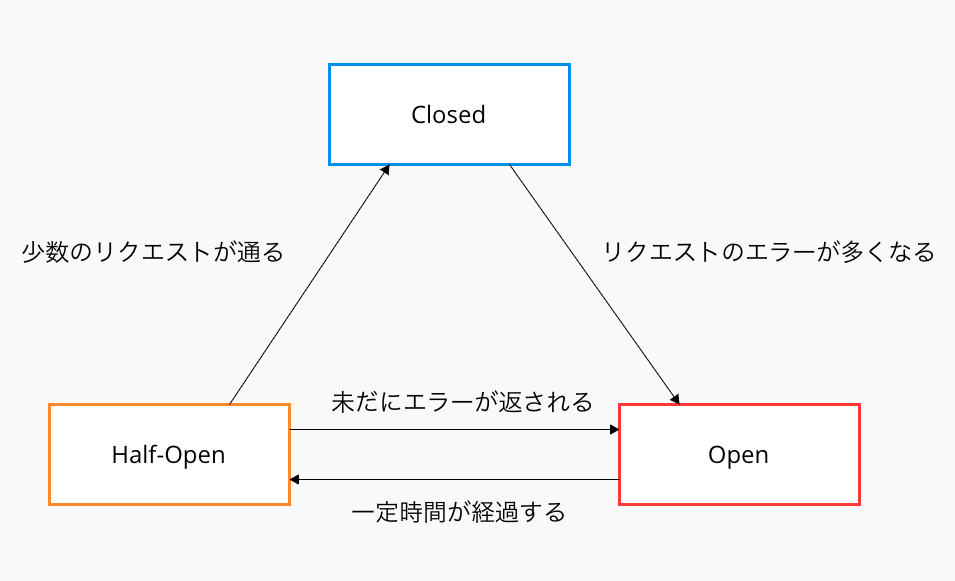
サーキットブレーカーでは以下の3つのステータスが定められている。
- Closed: リクエストがそのまま通る
Closed状態のサーキットブレーカーは、サービス間のエラーリクエストを監視する。AサービスからBサービスへのリクエストで正常に処理されなかったリクエスト数をカウント。
サーキットブレーカーを使用する際には、一般的にリクエストのエラー数に関するパラメータが事前に定義される。このパラメータを上回らない限り、ステータスはClosedであり続け、Bサービスへのリクエストは問題なく行われると判定される。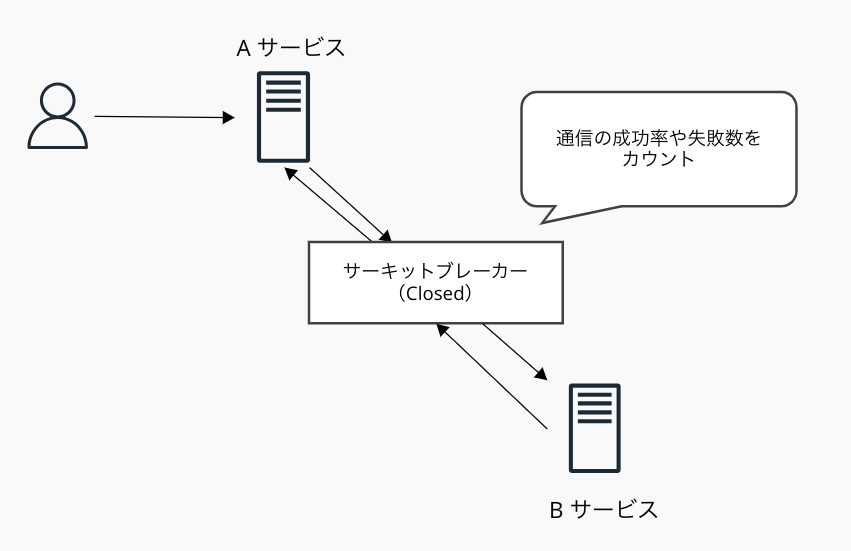
- Open: サーキットブレーカーによって、即座にエラーが返される
リクエストのエラー数が定義されたパラメータを上回った場合、ステータスはOpenとなる。
サーキットブレーカーの挙動として、Bサービスまで通信を介さず、Aサービスへ即座にエラーを返すようになる。これによりリクエストがタイムアウトするまでの時間を短縮し、ユーザーの待機時間を短縮することで体験の向上が見込める。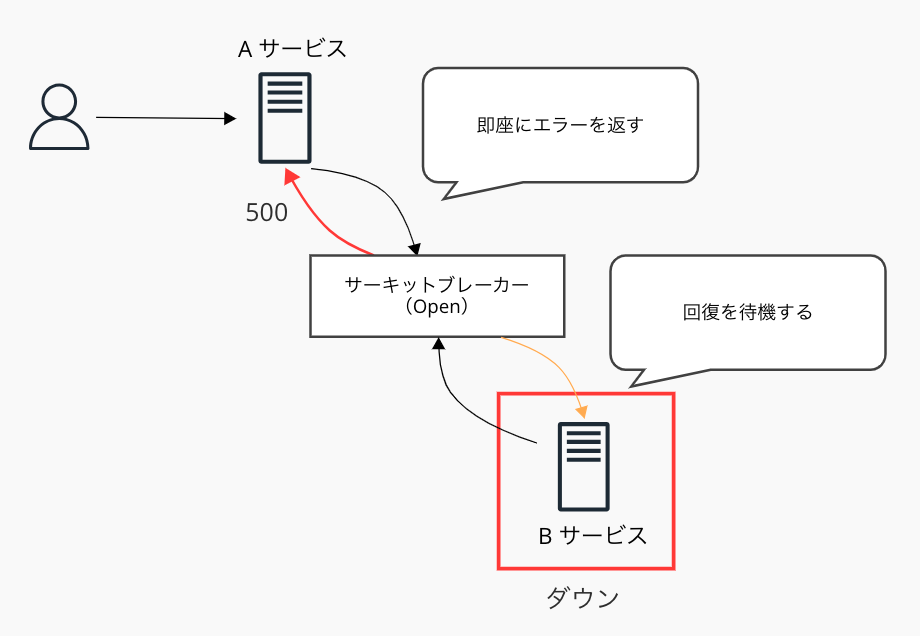
- Half-Open: Closed状態に遷移できるかどうか、少数のリクエストでチェックする
Open状態から一定の時間が経過した後、自動的にHalf-Openに遷移する。
少数のリクエストで通信ができるかどうかチェックを行い、できたらClosedへ、できなかったら再びOpenへ戻る。
もしリクエストが成功すると判定されClosedに遷移する場合は、内部のリクエストのエラーカウント数をリセット。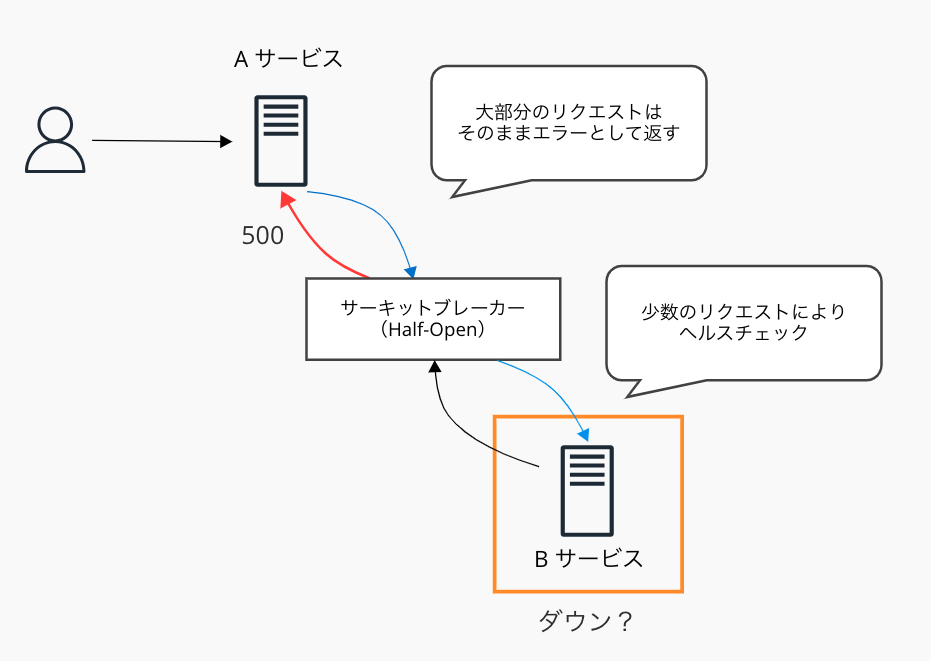
ステータスの遷移をまとめると
Notary
コンテナイメージに暗号化署名を付与するCNCFのプロジェクトで、配布されているコンテナイメージが、途中で改ざんされていないことを署名によって確認できる。
同プロジェクトは、すべてのレジストリで使用可能な署名フレームワークを構築して、署名をイメージと一緒にプッシュおよびプルできるようにすることで、オンプレミスのプライベートレジストリからプルしたイメージがDockerオフィシャルと同じであることを識別可能にすることを目指している。
kubernetes フェデレーション(KubeFed)
複数の Kubernetes クラスタを単一のエンティティとして管理することを可能にするKubernetes アーキテクチャの一種。
Kubernetes フェデレーションでは、単一のコントロールプレーンが複数のクラスタに接続し、それ
らの状態を追跡し、管理者がポリシーを適用したり、リソースをそれらのクラスタ全体にデプロイしたりすることを可能にする。
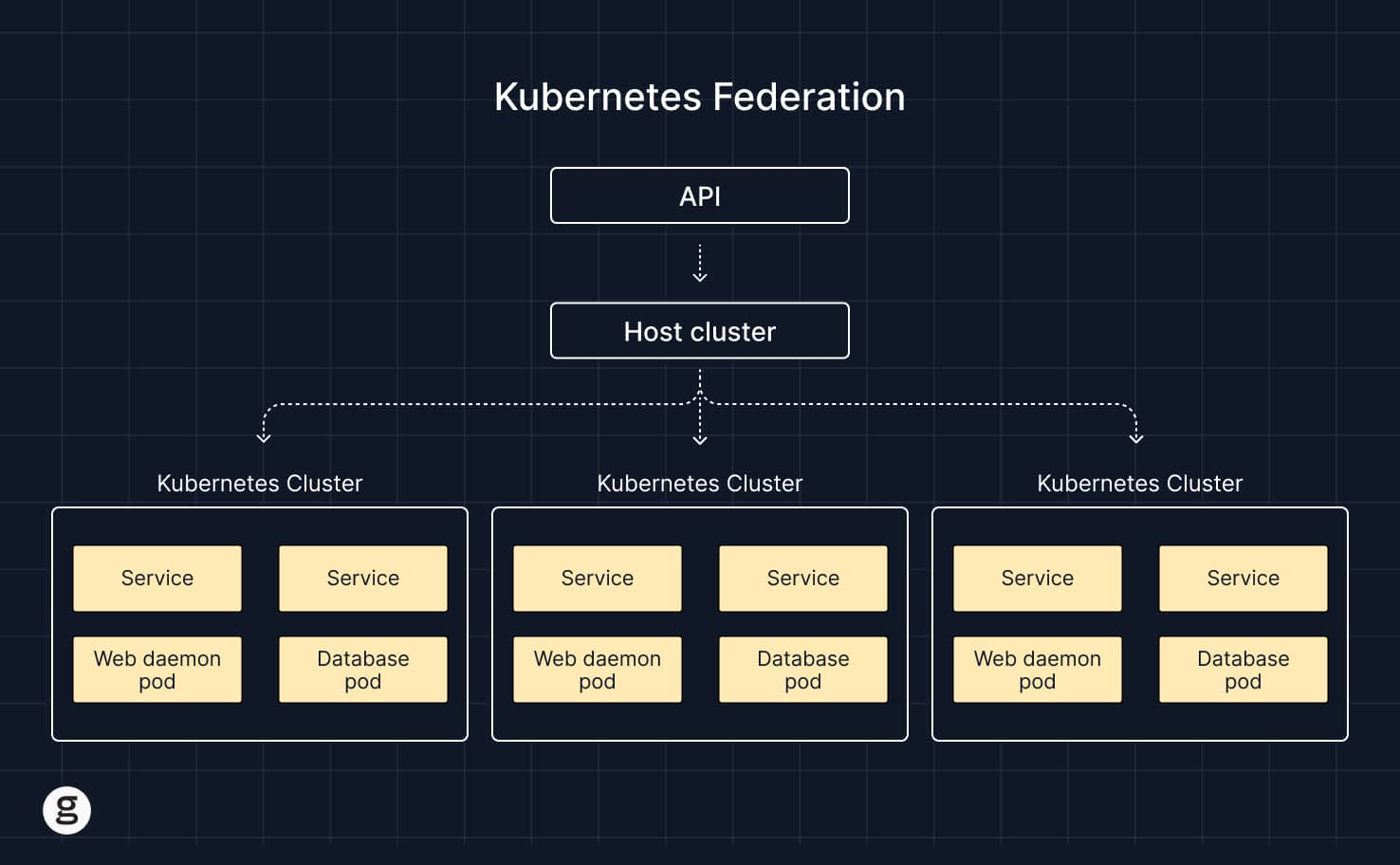
| マルチクラスタ Kubernetes | フェデレーテッドクラスタ | |
|---|---|---|
| API操作 | 各クラスタのAPIは完全に独立している。 | 統一されたAPIがすべてのクラスタを管理する。 |
| 集中型コントロールプレーン | なし。 | あり。 |
| クラスタアーキテクチャ | 各クラスタは独立して動作する。 | ホストクラスタが複数のワーカークラスタを管理する。 |
Kubernetes Event-Driven Autoscaling (KEDA)
Kubernetesベースのイベント駆動オートスケーラー。KEDAを使用すると、処理する必要があるイベントの数に基づいて、Kubernetes内の任意のコンテナのスケーリングを制御できる。
メッセージキューの長さやHTTPリクエストなどの外部メトリクスに基づいてアプリケーションをスケ
ーリングすることで、Kubernetesでイベント駆動のオートスケーリングを実現。この目的のために、ScaledObjectsと呼ばれるカスタムリソースを利用する。ScaledObjectsは、これらの外部メトリクスに基づいてアプリケーションをスケーリングする方法を定義。
KEDAは、Horizontal Pod Autoscalerなどの標準的なKubernetesコンポーネントと連携して動作し、上書きや重複なしに機能を拡張できる。
イベント駆動スケールを使用したいアプリを明示的にマッピングできながら他のアプリは引き続き機能する。これにより、KEDAは他の任意の数のKubernetesアプリケーションやフレームワークと並行して実行できる柔軟で安全なオプションとなる。
KEADではワークロードのpod数を0にスケールインすることも可能。(メッセージキューに何も入ってない時など)
Special Interest Group
Kubernetesプロジェクト内の特定のトピックや関心分野を中心にコミュニティを組織化・構造化する。各SIGは独自の憲章、目標、リーダーシップを持ち、議論、協力、意思決定のためのフォーラムを提供。



